Hi Experts,
I have one face detection application using TVM. And the data flow as following diagram, and all process is in the same thread:
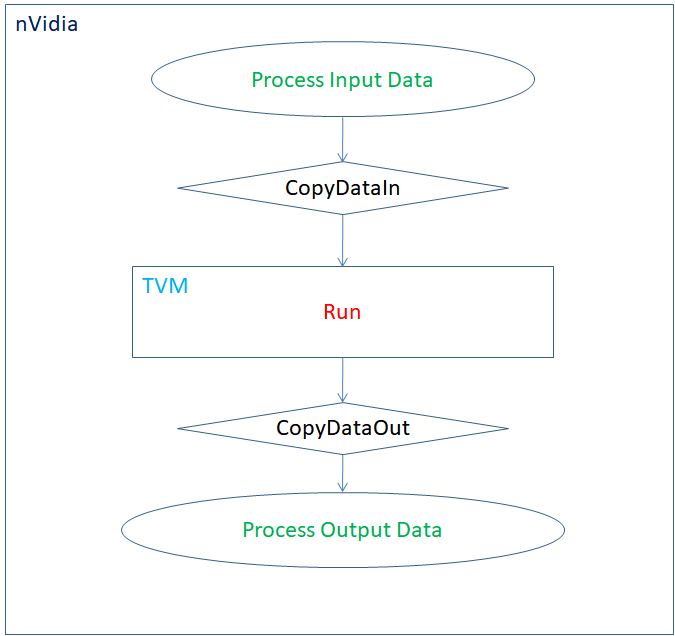
In nVidia GPU Environment.
I found the first cudaStreamSynchronize call cost much long time after calling my asynchronous kernel(in Process Output Data). And my kernel aims to process small data. As the image(captured from NIVIDIA Nsight Systems) shows, it costs more than 47ms, but the cost after the first kernel is small:

If i do not call run or call cudaDeviceSynchronize right after calling run, all cudaStreamSynchronize will not cost much time, as the image shows:
1, if do not call run, all cudaStreamSynchronize and kernel run fast:

2, if call cudaDeviceSynchronize right after calling run, and cudaDeviceSynchronize cost much time, and all cudaStreamSynchronize and kernel run fast:

Also, i found that no matter how large the input data size is, all the cost time of the run is the same (just more than 1ms and less than 2ms). And i think it is not possible if the run is synchororized.
So, i guess:
synchronize should be called explicitly.
And i really hope any experts can help confirming this.
Thanks in advance!!!