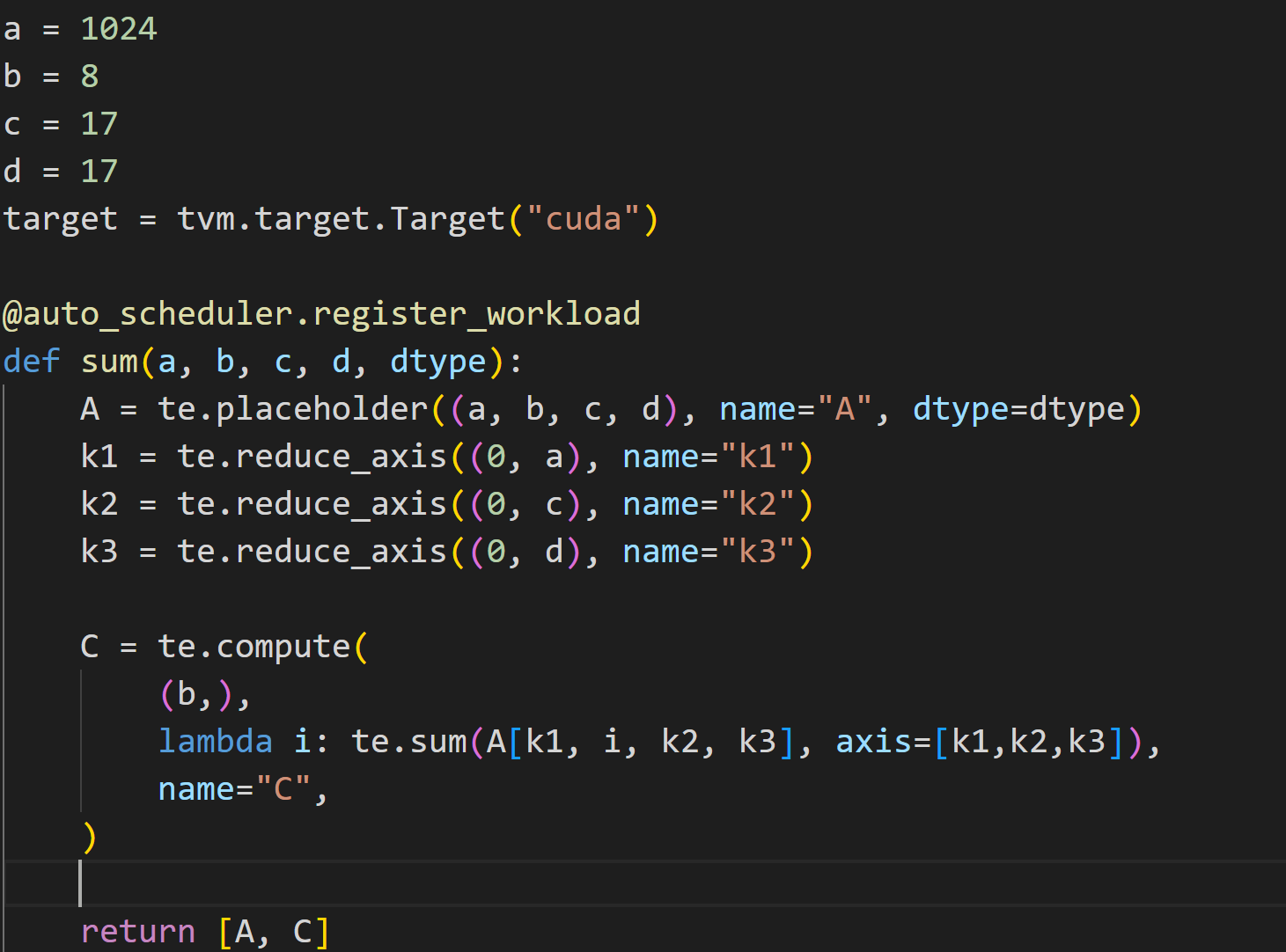
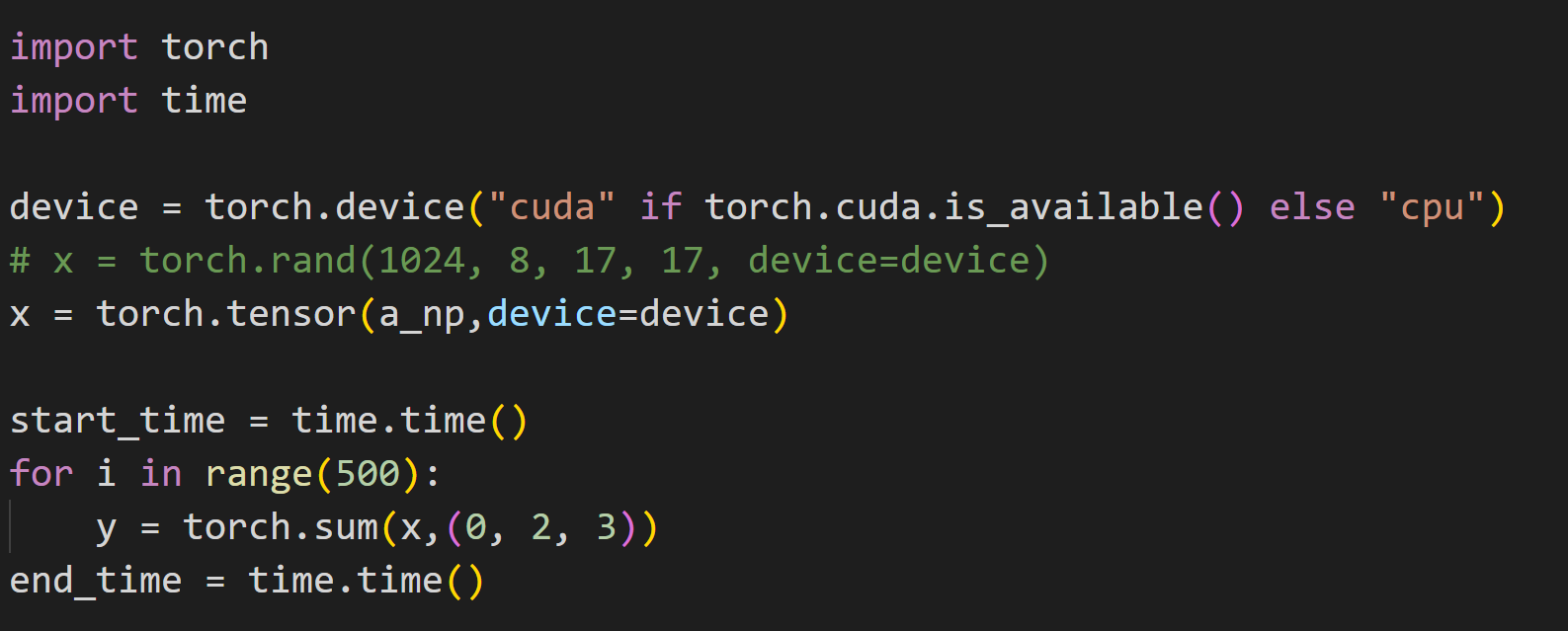
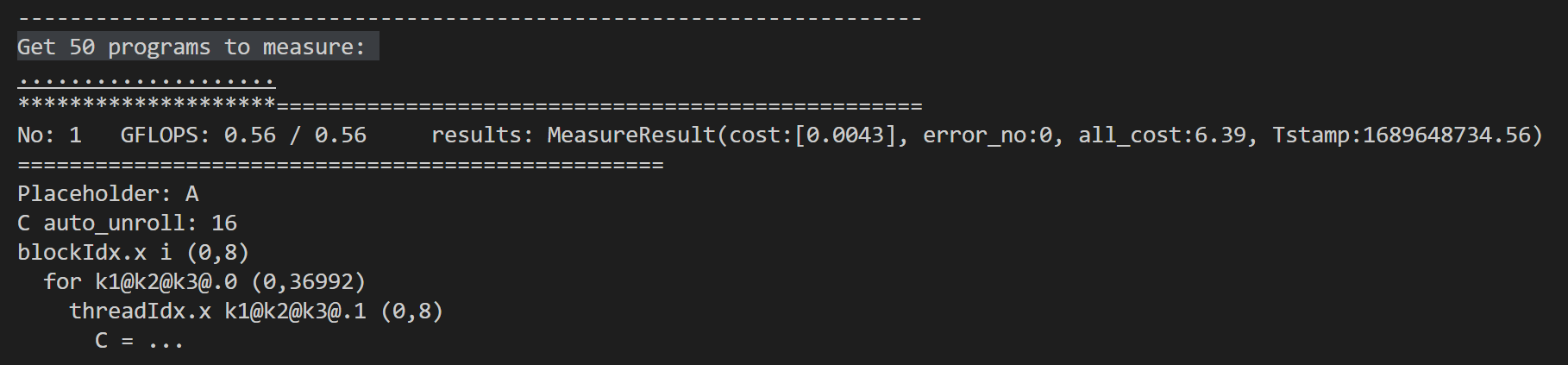
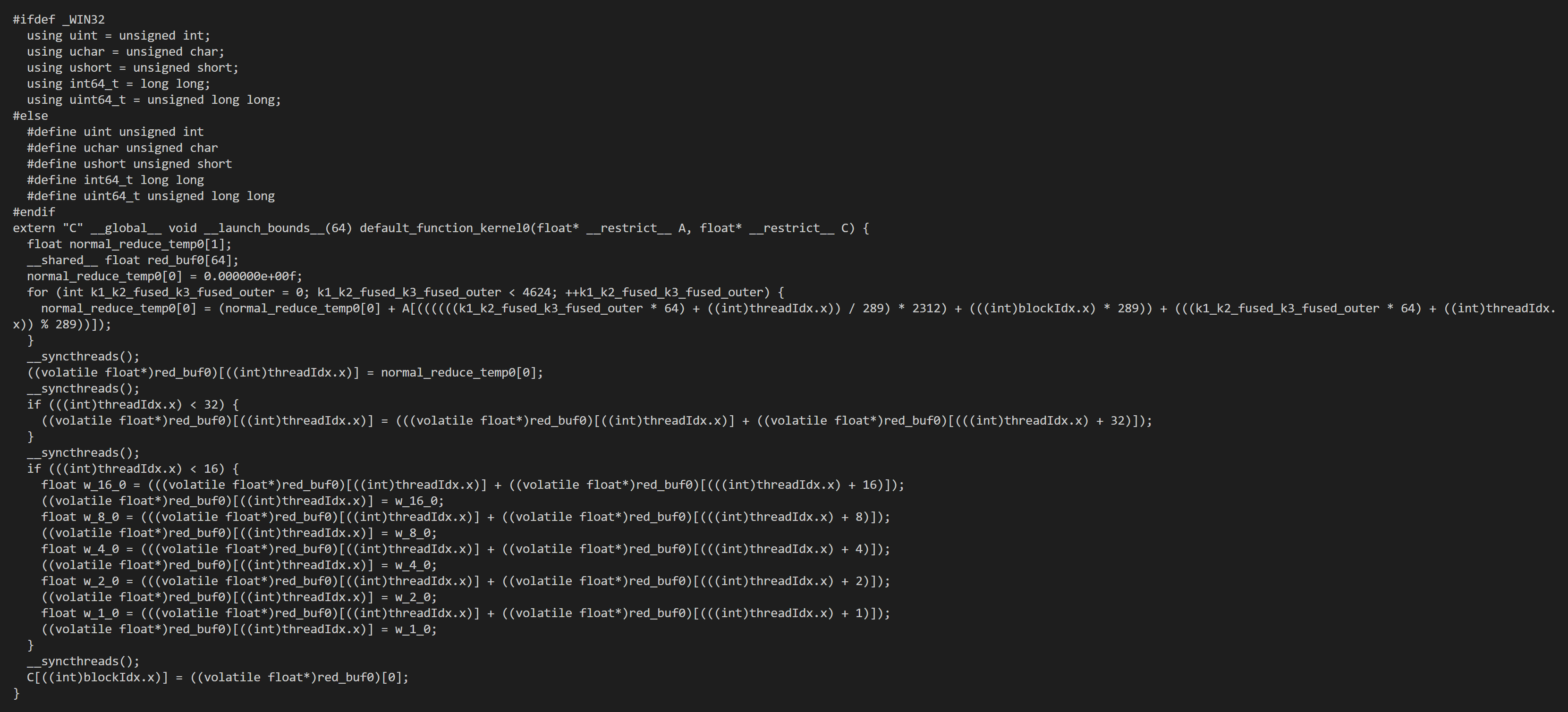
I also encountered the same problem when searching for reduce_sum on Ansor. The result of Ansor is 30x slower than torch.sum. I printed the cuda code found and found that its implementation is very ordinary, and printed Get 50 programs to measure. Is this a bug of Ansor?