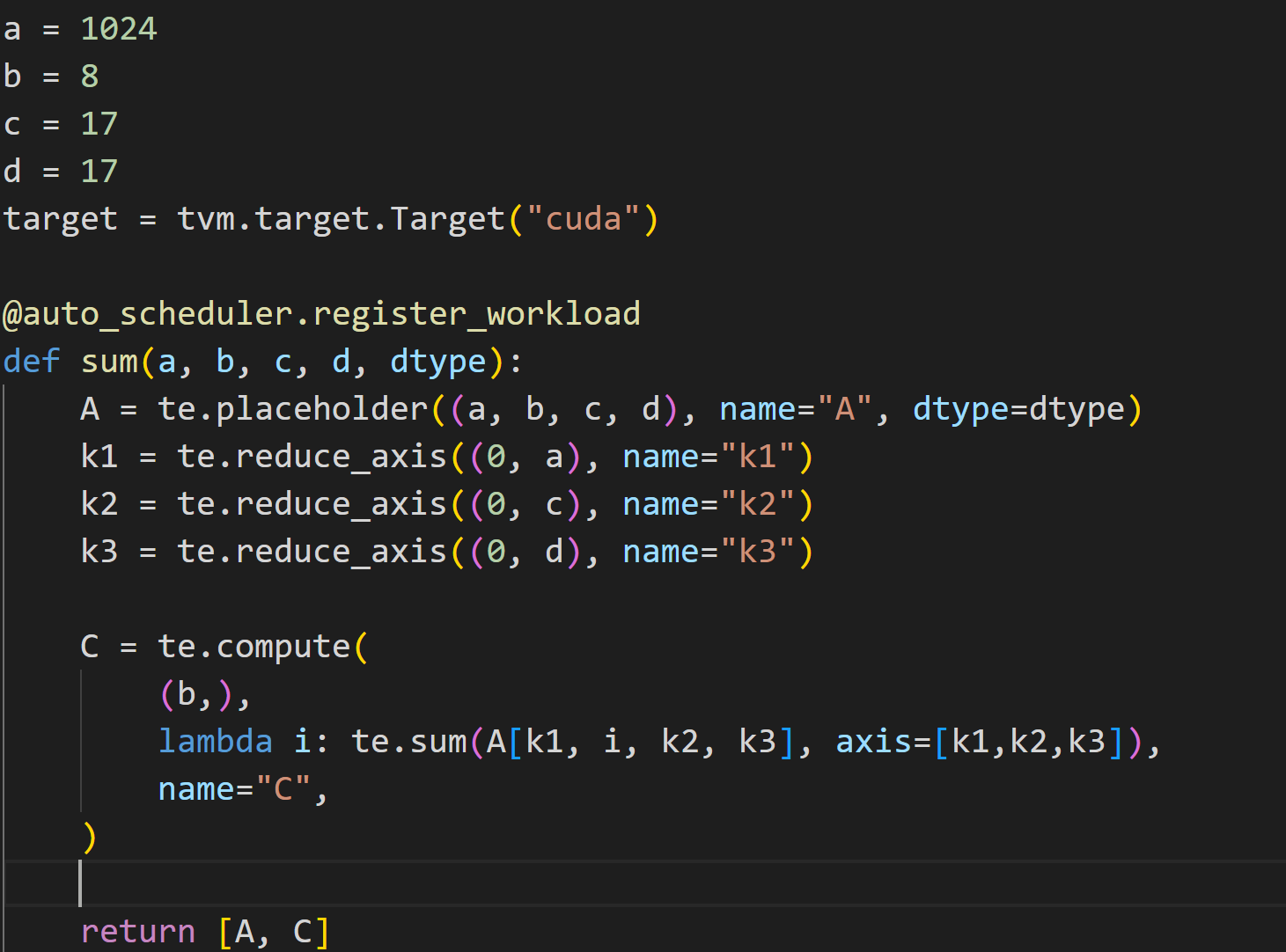
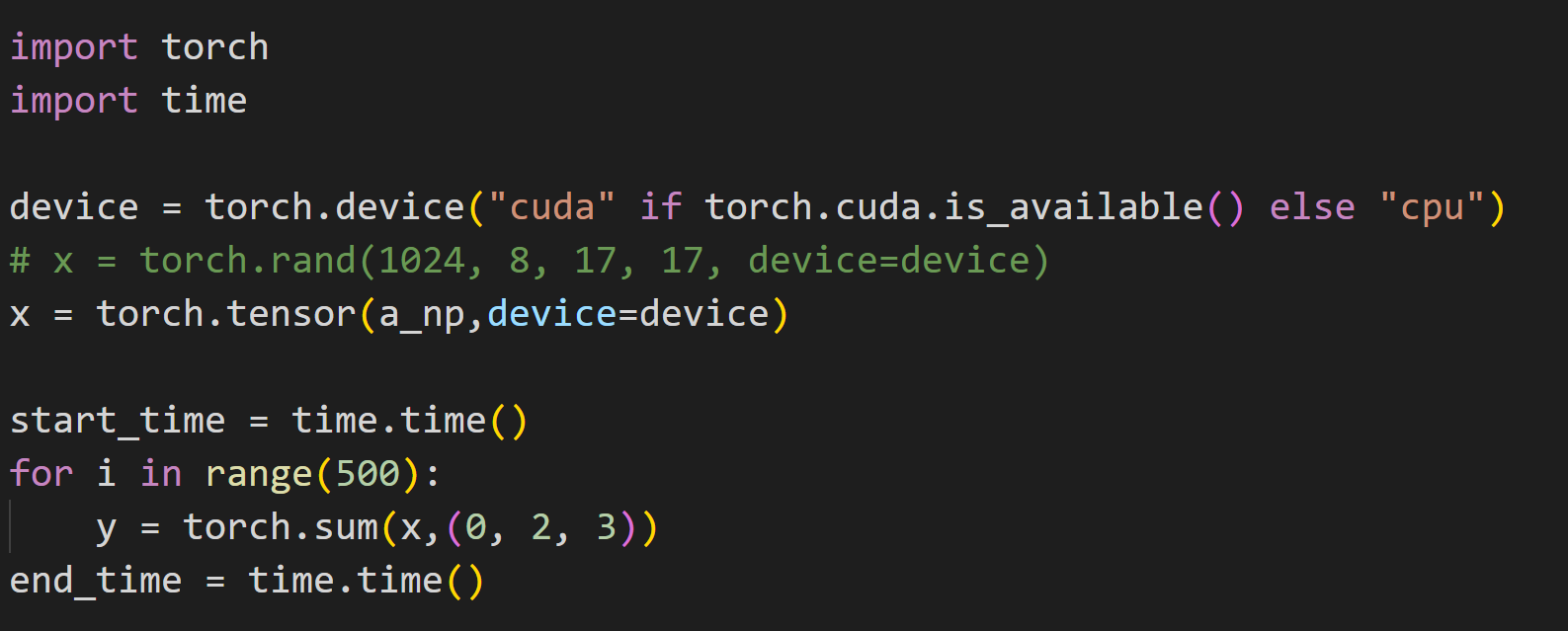
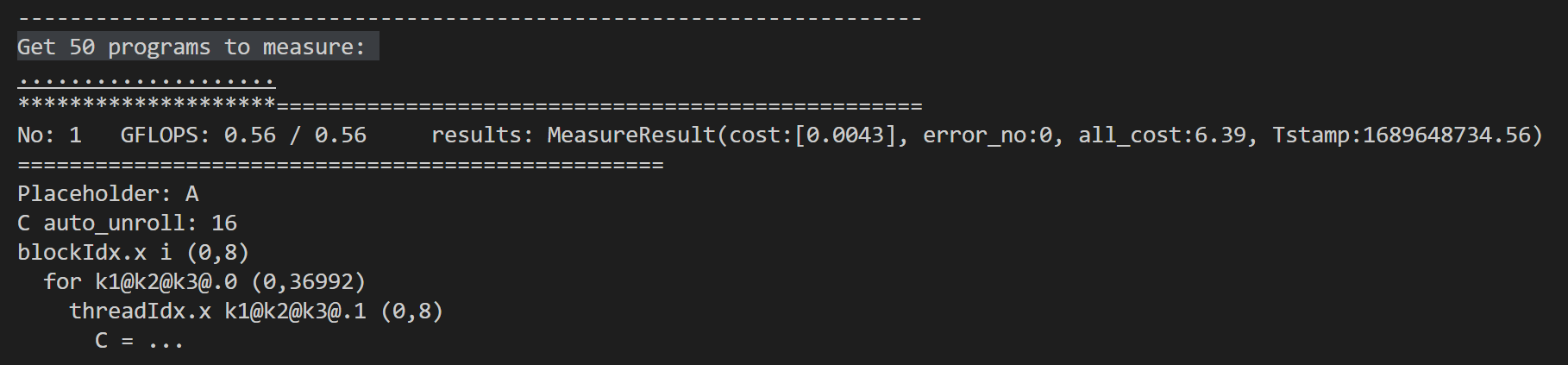
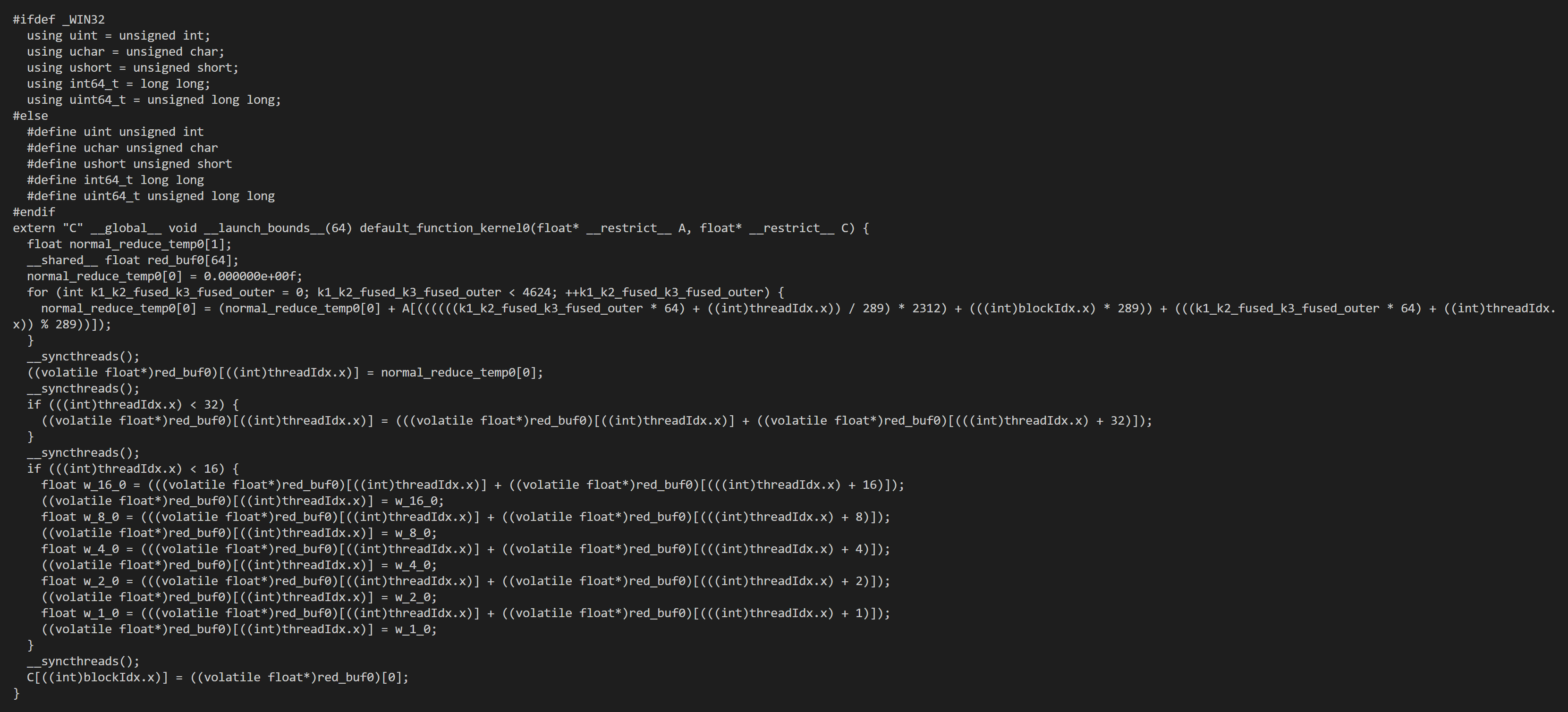
Hi all, I used tvm to generate code for reduce_sum on cuda.
It generates this code, seems it uses shared_memory, but seems the more efficient way is to use warp shuffle instructions, could tvm support it?
extern "C" __global__ void __launch_bounds__(1024) tvmgen_default_fused_add_nn_relu_sum_kernel0(float* __restrict__ p0, float* __restric
t__ p1, float* __restrict__ T_relu_red) {
float T_relu_red_rf[1];
__shared__ float red_buf0[1024];
T_relu_red_rf[0] = 0.000000e+00f;
if (((int)threadIdx.x) < 4) {
T_relu_red_rf[0] = (T_relu_red_rf[0] + max((p0[((int)threadIdx.x)] + p1[((int)threadIdx.x)]), 0.000000e+00f));
}
__syncthreads();
((volatile float*)red_buf0)[((int)threadIdx.x)] = T_relu_red_rf[0];
__syncthreads();
if (((int)threadIdx.x) < 512) {
((volatile float*)red_buf0)[((int)threadIdx.x)] = (((volatile float*)red_buf0)[((int)threadIdx.x)] + ((volatile float*)red_buf0)[(((
int)threadIdx.x) + 512)]);
}
__syncthreads();
if (((int)threadIdx.x) < 256) {
((volatile float*)red_buf0)[((int)threadIdx.x)] = (((volatile float*)red_buf0)[((int)threadIdx.x)] + ((volatile float*)red_buf0)[(((
int)threadIdx.x) + 256)]);
}
__syncthreads();
if (((int)threadIdx.x) < 128) {
((volatile float*)red_buf0)[((int)threadIdx.x)] = (((volatile float*)red_buf0)[((int)threadIdx.x)] + ((volatile float*)red_buf0)[(((
int)threadIdx.x) + 128)]);
}
__syncthreads();
if (((int)threadIdx.x) < 64) {
((volatile float*)red_buf0)[((int)threadIdx.x)] = (((volatile float*)red_buf0)[((int)threadIdx.x)] + ((volatile float*)red_buf0)[(((
int)threadIdx.x) + 64)]);
}
__syncthreads();
if (((int)threadIdx.x) < 32) {
((volatile float*)red_buf0)[((int)threadIdx.x)] = (((volatile float*)red_buf0)[((int)threadIdx.x)] + ((volatile float*)red_buf0)[(((
int)threadIdx.x) + 32)]);
}
__syncthreads();
if (((int)threadIdx.x) < 16) {
float w_16_0 = (((volatile float*)red_buf0)[((int)threadIdx.x)] + ((volatile float*)red_buf0)[(((int)threadIdx.x) + 16)]);
((volatile float*)red_buf0)[((int)threadIdx.x)] = w_16_0;
float w_8_0 = (((volatile float*)red_buf0)[((int)threadIdx.x)] + ((volatile float*)red_buf0)[(((int)threadIdx.x) + 8)]);
((volatile float*)red_buf0)[((int)threadIdx.x)] = w_8_0;
float w_4_0 = (((volatile float*)red_buf0)[((int)threadIdx.x)] + ((volatile float*)red_buf0)[(((int)threadIdx.x) + 4)]);
((volatile float*)red_buf0)[((int)threadIdx.x)] = w_4_0;
float w_2_0 = (((volatile float*)red_buf0)[((int)threadIdx.x)] + ((volatile float*)red_buf0)[(((int)threadIdx.x) + 2)]);
((volatile float*)red_buf0)[((int)threadIdx.x)] = w_2_0;
float w_1_0 = (((volatile float*)red_buf0)[((int)threadIdx.x)] + ((volatile float*)red_buf0)[(((int)threadIdx.x) + 1)]);
((volatile float*)red_buf0)[((int)threadIdx.x)] = w_1_0;
}
__syncthreads();
if (((int)threadIdx.x) == 0) {
T_relu_red[0] = ((volatile float*)red_buf0)[0];
}
}