
Thanks your reply,it works to me.And I want to ask that can tvm convert fp32 model to fp16 model?if can,does it use quantize to convert?
Hey wangbingjia, tvm can convert the model from fp32 → fp16 as you have seen. I am not sure what you mean by “use quantize to convert” but it also quantizes the weights and such of the model (or it should).
In general you need to apply some more optimizations to clean up the graph after FP16 quantization: https://github.com/AndrewZhaoLuo/TVM-Sandbox/blob/f1f9f698be2b7a8cc5bcf1167d892cd915eb7ce7/fp16_pass/benchmark_fp16.py#L19
As for tensorcore support, I believe autoscheduler does not support right now  and support in autotvm is inconsistent depending on workload. @masahi and @junrushao might know more about this though.
and support in autotvm is inconsistent depending on workload. @masahi and @junrushao might know more about this though.
I will say I have done some matrix heavy workloads in autotvm and gotten 5x speedup so its probably hitting the tensorcores there.
thanks @wangbingjia @comaniac @AndrewZhaoLuo for post, I also have interest for this model convert topic, I have a similar question like what @wangbingjia raised, the question is what is the main different between “relay.quantize” and “tvm.relay.transform.ToMixedPrecision” beside of “relay.quantize” did a float32 to int8 convert and “ToMixedPrecision” did a work to convert from float32 to float16 by default?
second question is about the a unified interface, some other framework like tflite which provide following unified model convert interface like following,
#to int8
converter.inference_input_type = tf.int8 # or tf.uint8
converter.inference_output_type = tf.int8 # or tf.uint8
tflite_quant_model = converter.convert()
#to fp16
converter.target_spec.supported_types = [tf.float16]
tflite_quant_model = converter.convert()
and current tvm used couple different interface mentioned before to provide the model convert function, is that helpful if these different interface/api can get wrapped with a single interface for example a function call “convert” or “quantize”?
Yep,thanks your reply.My graduation thesis is about TVM, and I am also very interested in TVM.About tensorcore question, I will try as you say.
Q1:As I know, if I want to convert fp32 model to fp16 model in tvm, there are two ways,one is use " tvm.relay.transform.ToMixedPrecision", another way is use “relay.quantize.qconfig”.I don’t know if what I said is correct.
Q2:And after I use the TVM interface to reduce the model accuracy to int8, the inference speed is reduced by more than 50 times.is this normal?? I am trying to locate this problem. Or later I will try to use the quantified model to optimize.
Q3:As @hjiang say,that is my question too.
Q1. relay.quantize.qconfig has to do with int8 quantization I believe. Integers in this space map back to the real numbers via an affine transforms stored in the qconfigs. This is not relevant to FP16. FP16 uses floating point format still, it just has less bits in the mantissa and exponent. If you want to convert to fp16 you should use ToMixedPrecision only. FP16 quantization and Integer quantizations are quite different.
Q2. There are a lot of variables here. In general if you are using the autoscheduler to schedule, you might see speed-downs since I believe it lacks support for using hardware intrinsics like vectorization with integers. It’s hard to add too which is why no one has done it yet. With autotvm, some operators support int8 quantization well (e.g. they use hardware intrinsics well) and others do not.
In short, the answer is complicated and depends on the model and how you tuned/ran the model. 5x speed downs I have seen in the past due to gaps in integer support on the scheduling level. FP16 quantization is very good if you have hardware which supports it well (e.g. a new enough ARM (ISA v8.2+), a GPU, something opencl supports with FP16 intrinsics)
Q3. @hjiang we do not have a unified interface. Instead use ToMixedPrecision for lower-bit floating point quantization (e.g. fp16 or bfloat16). It might be an interesting idea to add, though our int8 automatic quantization needs a bit of work first. IMO though fp16 and integer quantization are quite different and have different needs (e.g. integer you should have a calibrating dataset while fp16 you don’t necessarily need to)
1 Like
Thank you very much for your reply! your reply has answered my confusion, I will try to use the way you said.
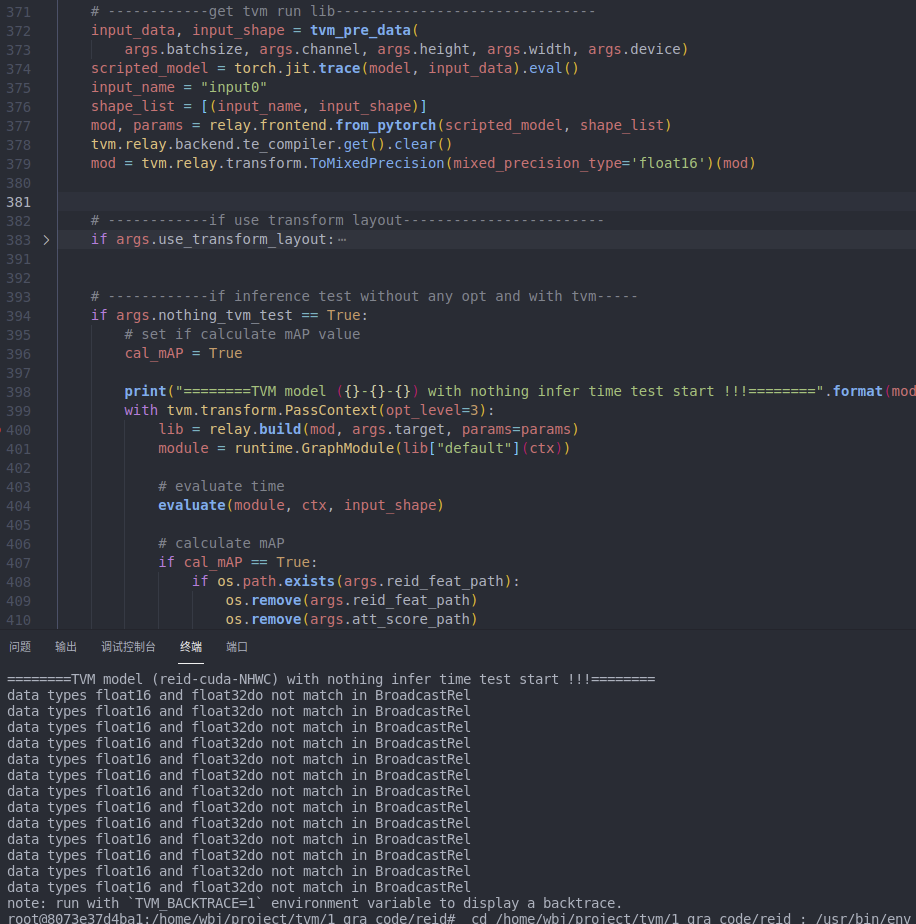
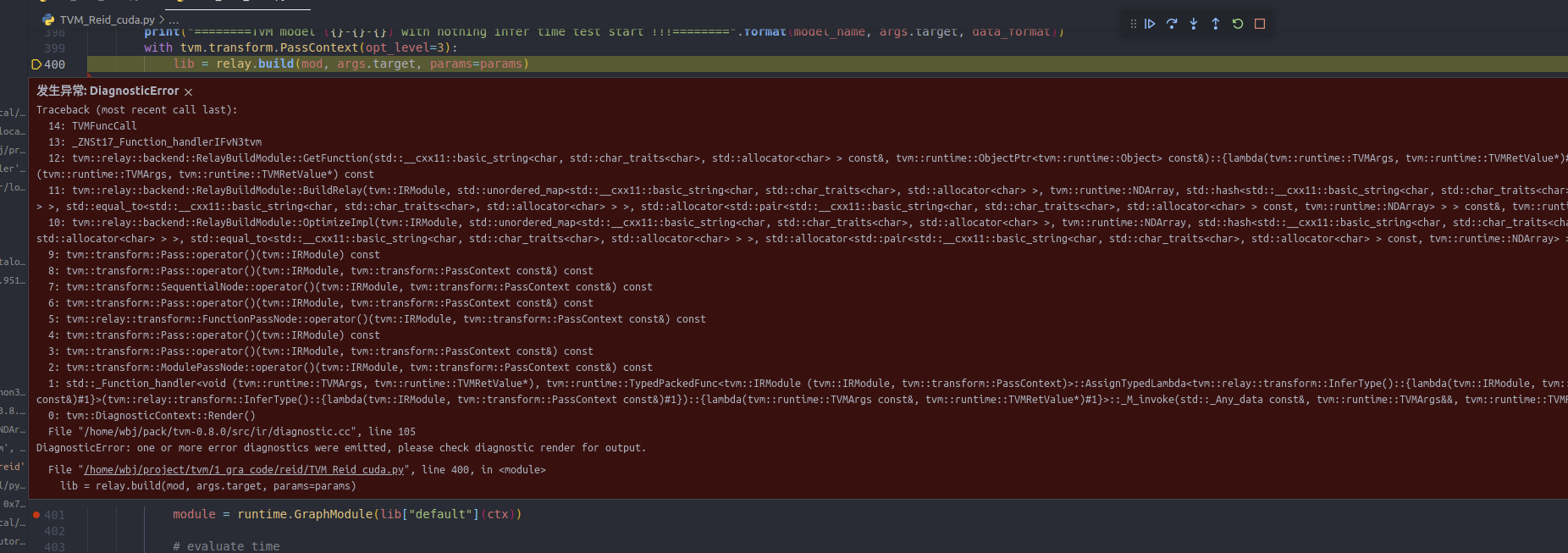
If you share your model I can help debug, this appears to be an operator which did not get converted correctly.
Yes, of course.I think it might be because of “InstanceNorm2d”, when I remove “InstanceNorm2d”, it works.After using fp16 precision, it is much faster than directly using “relay.quantize” to convert to int8, although they are not as fast as the original fp32.
import torch
import torch.nn as nn
from collections import namedtuple
import math
import torch.utils.model_zoo as model_zoo
__all__ = ['ResNet_IBN', 'resnet50_ibn_a']
model_urls = {
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
}
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class IBN(nn.Module):
def __init__(self, planes):
super(IBN, self).__init__()
half1 = int(planes / 2)
self.half = half1
half2 = planes - half1
self.IN = nn.InstanceNorm2d(half1, affine=True)
self.BN = nn.BatchNorm2d(half2)
def forward(self, x):
split = torch.split(x, self.half, 1)
out1 = self.IN(split[0].contiguous())
out2 = self.BN(split[1].contiguous())
out = torch.cat((out1, out2), 1)
return out
class Bottleneck_IBN(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, ibn=False, stride=1, downsample=None):
super(Bottleneck_IBN, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
if ibn:
self.bn1 = IBN(planes)
else:
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet_IBN(nn.Module):
def __init__(self, last_stride, block, layers, frozen_stages=-1, num_classes=1000):
scale = 64
self.inplanes = scale
super(ResNet_IBN, self).__init__()
self.conv1 = nn.Conv2d(3, scale, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(scale)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.frozen_stages = frozen_stages
self.layer1 = self._make_layer(block, scale, layers[0])
self.layer2 = self._make_layer(block, scale * 2, layers[1], stride=2)
self.layer3 = self._make_layer(block, scale * 4, layers[2], stride=2)
self.layer4 = self._make_layer(block, scale * 8, layers[3], stride=last_stride)
self.avgpool = nn.AvgPool2d(7)
self.fc = nn.Linear(scale * 8 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.InstanceNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(planes * block.expansion),)
layers = []
ibn = True
if planes == 512:
ibn = False
layers.append(block(self.inplanes, planes, ibn, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, ibn))
return nn.Sequential(*layers)
def _freeze_stages(self):
if self.frozen_stages >= 0:
self.bn1.eval()
for m in [self.conv1, self.bn1]:
for param in m.parameters():
param.requires_grad = False
for i in range(1, self.frozen_stages + 1):
m = getattr(self, 'layer{}'.format(i))
print('layer{}'.format(i))
m.eval()
for param in m.parameters():
param.requires_grad = False
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x3 = x
x = self.layer4(x)
return x, x3
# return x
# def load_param(self, model_path):
def load_param(self, model_path='E:/model/resnet50_ibn_a.pth'):
param_dict = torch.load(model_path)
print(param_dict)
print('*'*60)
if 'state_dict' in param_dict:
param_dict = param_dict['state_dict']
for i in param_dict:
if 'fc' in i:
continue
self.state_dict()[i.replace('module.', '')].copy_(param_dict[i])
ArchCfg = namedtuple('ArchCfg', ['block', 'layers'])
arch_dict = {
#'resnet18': ArchCfg(BasicBlock, [2, 2, 2, 2]),
#'resnet34': ArchCfg(BasicBlock, [3, 4, 6, 3]),
'resnet50': ArchCfg(Bottleneck_IBN, [3, 4, 6, 3]),
'resnet101': ArchCfg(Bottleneck_IBN, [3, 4, 23, 3]),
'resnet152': ArchCfg(Bottleneck_IBN, [3, 8, 36, 3]),}
def resnet50_ibn_a(last_stride=1, pretrained=False, **kwargs):
"""Constructs a ResNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet_IBN(last_stride, Bottleneck_IBN, [3, 4, 6, 3], **kwargs)
block_dict = dict()
if pretrained:
state_dict = torch.load('E:/model/resnet50_ibn_a.pth')
print('Load pretrained model from ===> E:/model/resnet50_ibn_a.pth')
model.load_param('E:/model/resnet50_ibn_a.pth')
# print(state_dict.items())
for k, v in state_dict.items():
# print(k, v)
if 'layer4.' in k:
block_dict.update({k: v})
return model
#def get_resnet50_org():
# model = ResNet_IBN(last_stride=1, arch_dict['resnet50'].block, arch_dict['resnet50'].layers)
# return model
# if __name__ == '__main__':
# import torch
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # PyTorch v0.4.0
#
# model = resnet50_ibn_a(pretrained=False)
# input = torch.randn(1, 3, 384, 128)
# out1, out2 = model(input)
# print(out1.shape)
# print(out2.shape)
# print('&'*80)
# # print(y.shape)
# # print(x3.shape)
I’ll take a closer look this week. As for speed, which type of device are you running this on? Not all targets, most notably x86 CPU has good support for fp16.
Do you have a specific demo of fp16 reasoning, the example in cuda? Can you learn from it
This entire repo should be helpful though does not use CUDA. You should be able to adapt this to run on CUDA easily: https://github.com/AndrewZhaoLuo/CenterFaceTVMDemo.
An issue IIRC with CUDA is our tensorcore support is a bit fuzzy at this time so you might not see as high speedups as with tensorrt for example.
Thanks, I’ll take a look
MetaSchedule support Tensor Cores.
thank you. I have seen MetaScheduler today, is there any document for about how to use MetaScheduler?
Unfortunately, the documentation for metaschedule is poor.
There is an API reference doc: tvm.meta_schedule — tvm 0.14.dev0 documentation but I don’t think it is informative enough for new users.
The unit tests might help you find some examples of using meta-schedule, for example:
Besides, this paper might help you understand the design of Metaschedule.
@twmht There is the Machine Learning Compilation course material that can be a reference for using MetaSchedule: 4. Automatic Program Optimization — Machine Learing Compilation 0.0.1 documentation
To use TensorCore, I didn’t try but feel you can use some code similar below
from tvm import meta_schedule as ms
database = ms.tir_integration.tune_tir(
mod=your_tir_function,
target="nvidia/geforce-rtx-3080",
work_dir="database",
max_trials_global=2000,
num_trials_per_iter=32,
space=ms.space_generator.PostOrderApply(
sch_rules="cuda-tensorcore",
postprocs="cuda-tensorcore",
mutator_probs="cuda-tensorcore",
),
)
@MasterJH5574 this is great, I have seen a similar usage for compiling torchscript model( tvm/python/tvm/contrib/torch/optimize_torch.py at main · apache/tvm (github.com)), the remining quesion is that how can i export the compiled model for reuse?
Hello, I am trying to quantize a resnet50 tflite model from fp32 to fp16 via the ToMixedPrecision Pass. This post was very useful for me to set the required stuff for me to proceed with quantization.
Coming to my issue, I first downloaded a ResnetNet50V2 model using the Keras Applications API, quantised it to fp16 and then converted it to a tflite model.
However, when I check the graph of the quantised model on Netron, I see this:
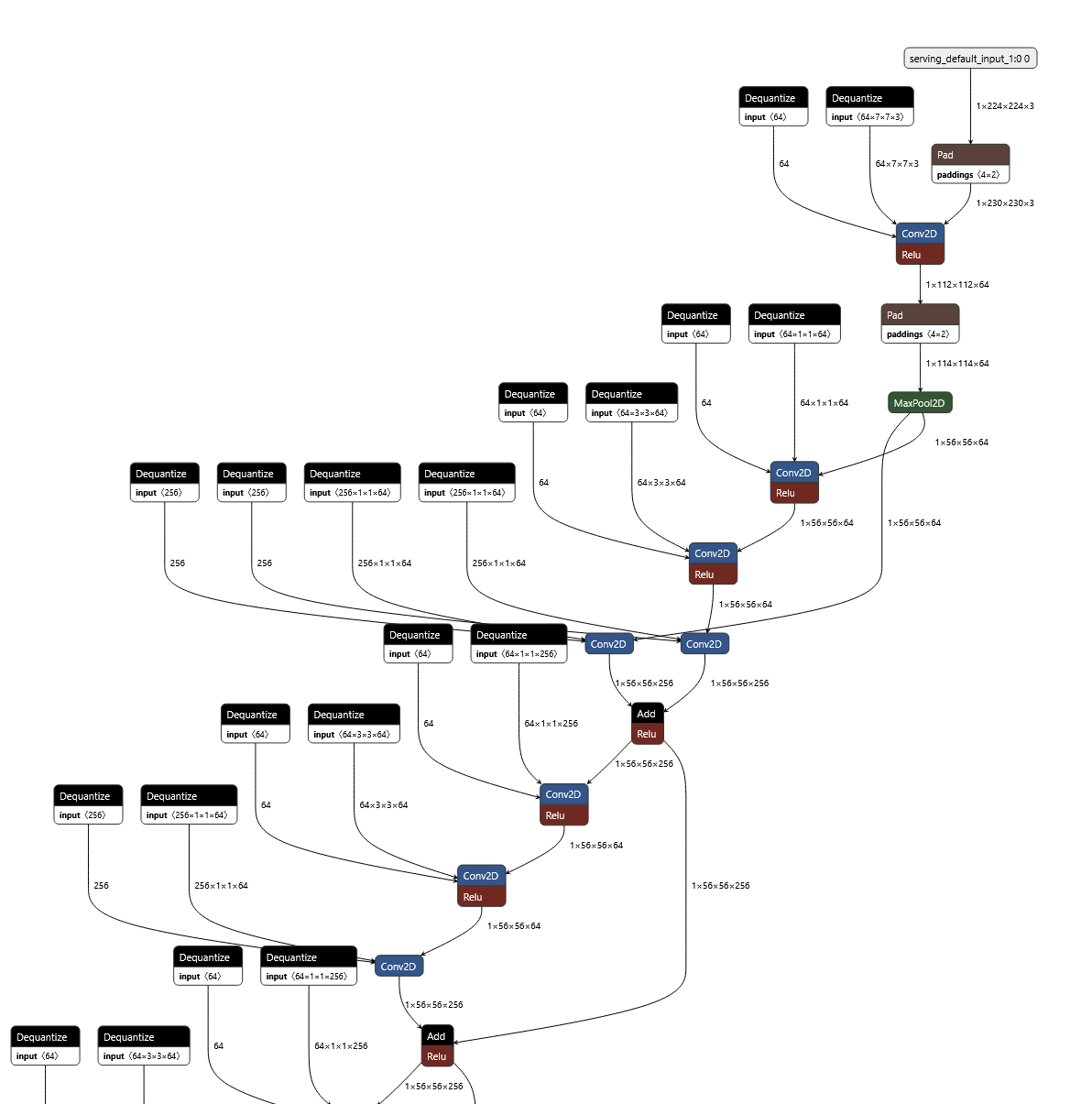
Further, the input layer looks like this :

And a Conv layer looks like this:
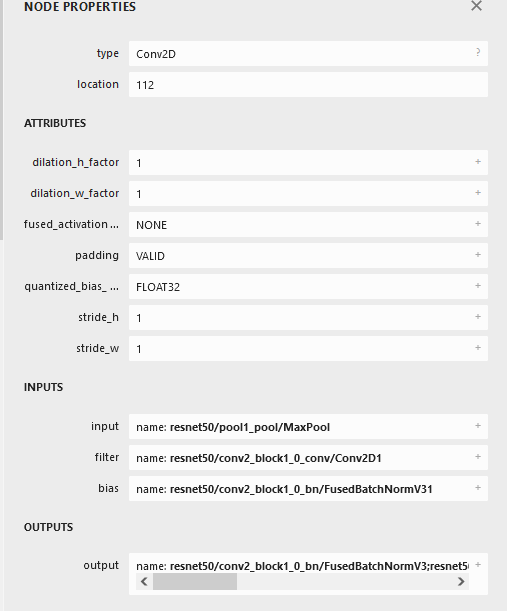
I do not understand why the datatypes still show up as float32 in the conv layer.
The code which performed this quantizaton is :
Representative dataset gen:
test_datagen = ImageDataGenerator(preprocessing_function=preprocess_input)
test_generator = test_datagen.flow_from_directory(TEST_DATA_DIR,
target_size=(IMG_WIDTH, IMG_HEIGHT),
batch_size=1, shuffle=False,
class_mode='categorical')
def represent_data_gen():
""" it yields an image one by one """
for ind in range(len(test_generator.filenames)):
img_with_label = test_generator.next() # it returns (image and label) tuple
image = np.array(img_with_label[0], dtype=np.float32, ndmin=2)
# image = image.reshape((1,3,224,224))
# print(image.shape)
yield [image] # return only image
Actual quantization and conversion: # CONVERSION TO FP-16
# convert a tf.Keras model to tflite model
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16] # save them in float16
converter.representative_dataset = represent_data_gen
tflite_model = converter.convert()
# write the model to a tflite file as binary file
with open("resnet50_imagenet_both-fp16-quant-nov9.tflite", "wb") as f:
f.write(tflite_model)
The ToMixedPrecision Pass is like this:
def graph_optimize(mod, params, run_fp16_pass, run_other_opts):
mod = tvm.IRModule.from_expr(mod["main"])
if run_other_opts:
mod = tvm.relay.transform.FastMath()(mod)
mod = tvm.relay.transform.EliminateCommonSubexpr()(mod)
BindPass = tvm.relay.transform.function_pass(
lambda fn, new_mod, ctx: tvm.relay.build_module.bind_params_by_name(
fn, params
),
opt_level=1,
)
mod = BindPass(mod)
mod = tvm.relay.transform.FoldConstant()(mod)
mod = tvm.relay.transform.CombineParallelBatchMatmul()(mod)
mod = tvm.relay.transform.FoldConstant()(mod)
if run_fp16_pass:
mod = InferType()(mod)
mod = ToMixedPrecision()(mod)
if run_other_opts and run_fp16_pass:
# run one more pass to clean up new subgraph
mod = tvm.relay.transform.EliminateCommonSubexpr()(mod)
mod = tvm.relay.transform.FoldConstant()(mod)
mod = tvm.relay.transform.CombineParallelBatchMatmul()(mod)
mod = tvm.relay.transform.FoldConstant()(mod)
return mod, params
Finally, when I do an inference in tvm on cuda target on my GPU (NVIDIA A3000 enterprise GPU), I do not get any speedup/accelaration. I get similar times as a normal non-quantised fp32 resnet50 model.
Please help me in identifying where I am going wrong with fp16 quantization. TIA. @AndrewZhaoLuo