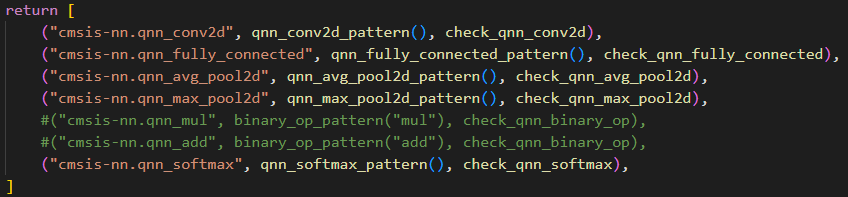
Hi Sirs,
I compared two ways of op add.
One is “arm_elementwise_add_s8” and the other one is composite function.
(they are generated by tvm codegen)
Inputs and Ouptut information:
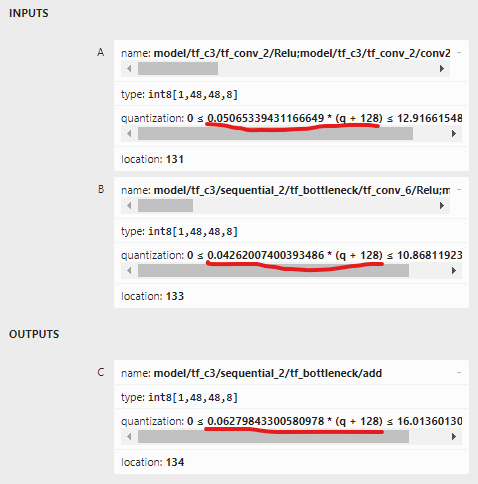
if input A is -109 and input B is -85, and we can calculate by hand and get the output is -83 (-83.491283)
Then we use the “arm_elementwise_add_s8”.
arm_elementwise_add_s8(input_0_, input_1_, 128, 1073741824, 0, 128, 1806905801, -1, 20, output_, -128, 1732166406, -19, -128, 127, 18432);
this is generated by tvm, and the output is -83 also (modify the last argument to 1)
Now we use the composite function, these are also generated by tvm.
###########################################################
for (int32_t ax0_ax1_fused_ax2_fused_ax3_fused = 0; ax0_ax1_fused_ax2_fused_ax3_fused < 18432; ++ax0_ax1_fused_ax2_fused_ax3_fused) {
((int32_t*)T_cast)[ax0_ax1_fused_ax2_fused_ax3_fused] = ((int32_t)placeholder[ax0_ax1_fused_ax2_fused_ax3_fused]);
}
for (int32_t ax0_ax1_fused_ax2_fused_ax3_fused1 = 0; ax0_ax1_fused_ax2_fused_ax3_fused1 < 18432; ++ax0_ax1_fused_ax2_fused_ax3_fused1) {
((int32_t*)T_cast)[ax0_ax1_fused_ax2_fused_ax3_fused1] = (((int32_t*)T_cast)[ax0_ax1_fused_ax2_fused_ax3_fused1] - ((int32_t*)fused_cast_constant_0)[0]);
}
for (int32_t i0_i1_fused_i2_fused_i3_fused = 0; i0_i1_fused_i2_fused_i3_fused < 18432; ++i0_i1_fused_i2_fused_i3_fused) {
((int32_t*)T_cast)[i0_i1_fused_i2_fused_i3_fused] = ((int32_t)(((((0 != 0) ? (((int64_t)((int32_t*)T_cast)[i0_i1_fused_i2_fused_i3_fused]) << ((int64_t)0)) : ((int64_t)((int32_t*)T_cast)[i0_i1_fused_i2_fused_i3_fused])) * (int64_t)1732166406) + ((int64_t)1 << ((int64_t)((0 + 31) - 1)))) >> ((int64_t)(0 + 31))));
}
for (int32_t ax0_ax1_fused_ax2_fused_ax3_fused2 = 0; ax0_ax1_fused_ax2_fused_ax3_fused2 < 18432; ++ax0_ax1_fused_ax2_fused_ax3_fused2) {
((int32_t*)T_cast)[ax0_ax1_fused_ax2_fused_ax3_fused2] = (((int32_t*)T_cast)[ax0_ax1_fused_ax2_fused_ax3_fused2] - 128);
}
for (int32_t ax0_ax1_fused_ax2_fused_ax3_fused3 = 0; ax0_ax1_fused_ax2_fused_ax3_fused3 < 18432; ++ax0_ax1_fused_ax2_fused_ax3_fused3) {
((int32_t*)T_cast1)[ax0_ax1_fused_ax2_fused_ax3_fused3] = ((int32_t)placeholder1[ax0_ax1_fused_ax2_fused_ax3_fused3]);
}
for (int32_t ax0_ax1_fused_ax2_fused_ax3_fused4 = 0; ax0_ax1_fused_ax2_fused_ax3_fused4 < 18432; ++ax0_ax1_fused_ax2_fused_ax3_fused4) {
((int32_t*)T_cast1)[ax0_ax1_fused_ax2_fused_ax3_fused4] = (((int32_t*)T_cast1)[ax0_ax1_fused_ax2_fused_ax3_fused4] - ((int32_t*)fused_cast_constant_0)[0]);
}
for (int32_t i0_i1_fused_i2_fused_i3_fused1 = 0; i0_i1_fused_i2_fused_i3_fused1 < 18432; ++i0_i1_fused_i2_fused_i3_fused1) {
((int32_t*)T_cast1)[i0_i1_fused_i2_fused_i3_fused1] = ((int32_t)(((((0 != 0) ? (((int64_t)((int32_t*)T_cast1)[i0_i1_fused_i2_fused_i3_fused1]) << ((int64_t)0)) : ((int64_t)((int32_t*)T_cast1)[i0_i1_fused_i2_fused_i3_fused1])) * (int64_t)1457455348) + ((int64_t)1 << ((int64_t)((0 + 31) - 1)))) >> ((int64_t)(0 + 31))));
}
for (int32_t ax0_ax1_fused_ax2_fused_ax3_fused5 = 0; ax0_ax1_fused_ax2_fused_ax3_fused5 < 18432; ++ax0_ax1_fused_ax2_fused_ax3_fused5) {
((int32_t*)T_cast1)[ax0_ax1_fused_ax2_fused_ax3_fused5] = (((int32_t*)T_cast1)[ax0_ax1_fused_ax2_fused_ax3_fused5] - 128);
}
for (int32_t ax0_ax1_fused_ax2_fused_ax3_fused6 = 0; ax0_ax1_fused_ax2_fused_ax3_fused6 < 18432; ++ax0_ax1_fused_ax2_fused_ax3_fused6) {
((int32_t*)T_cast)[ax0_ax1_fused_ax2_fused_ax3_fused6] = (((int32_t*)T_cast)[ax0_ax1_fused_ax2_fused_ax3_fused6] + ((int32_t*)T_cast1)[ax0_ax1_fused_ax2_fused_ax3_fused6]);
}
for (int32_t ax0_ax1_fused_ax2_fused_ax3_fused7 = 0; ax0_ax1_fused_ax2_fused_ax3_fused7 < 18432; ++ax0_ax1_fused_ax2_fused_ax3_fused7) {
((int32_t*)T_cast)[ax0_ax1_fused_ax2_fused_ax3_fused7] = (((int32_t*)T_cast)[ax0_ax1_fused_ax2_fused_ax3_fused7] + 128);
}
for (int32_t i0_i1_fused_i2_fused_i3_fused2 = 0; i0_i1_fused_i2_fused_i3_fused2 < 18432; ++i0_i1_fused_i2_fused_i3_fused2) {
int32_t _1 = ((int32_t*)T_cast)[i0_i1_fused_i2_fused_i3_fused2];
int32_t _2 = (_1) < (127) ? (_1) : (127);
((int32_t*)T_cast)[i0_i1_fused_i2_fused_i3_fused2] = ((_2) > (-128) ? (_2) : (-128));
}
for (int32_t ax0_ax1_fused_ax2_fused_ax3_fused8 = 0; ax0_ax1_fused_ax2_fused_ax3_fused8 < 18432; ++ax0_ax1_fused_ax2_fused_ax3_fused8) {
((int8_t*)T_cast1)[ax0_ax1_fused_ax2_fused_ax3_fused8] = ((int8_t)((int32_t*)T_cast)[ax0_ax1_fused_ax2_fused_ax3_fused8]);
}
#########################################################################
"placeholder " and “placeholder1” are input A and input B buffers.
“T_cast” and “T_cast1” are temporary buffers.
fused_cast_constant_0)[0] is -0x80
the output is -84
these two ways have different outputs, and it seems the arm api has the correct output (compare with calculate by hand)
But the inference result of using composite function is correct, and using arm add api is incorrect.
Can anyone help to explain this?
Thanks!