Thanks for your reply.
Actually, I still have some confusion regarding using such CPU affinity since I am not quite familiar with C++ backend.
Question 1:
According to your answer:
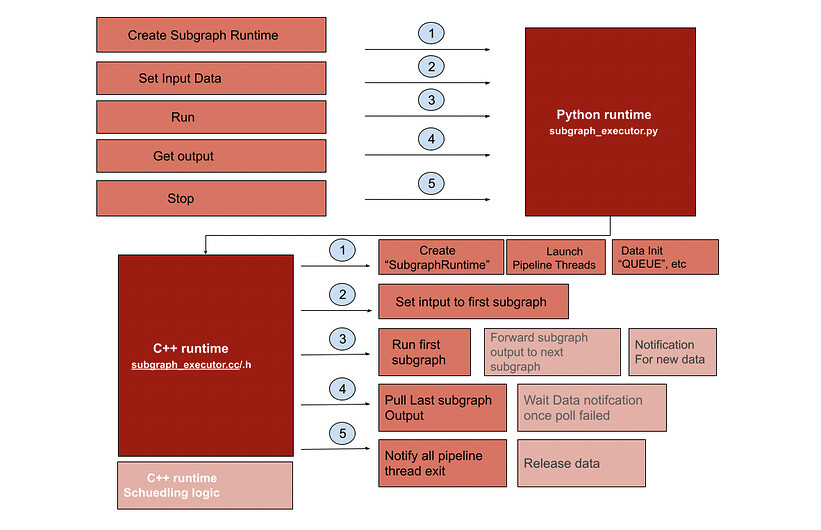
tvm::runtime::threading ::Configure is a c++ function, you only can call it in c++ library, after split compute graph into 2 sub-graph, you should run each sub-graph with specify runtime in different thread and call the said function =>
So my understanding is that the users cannot use python function to call such C++ function as you do in pipeline_executors:
What is the meaning of concurrency_config in the following Configure?
"tvm::runtime::threading ::Configure(tvm::runtime::threading::ThreadGroup::kSpecify, 0, cpus, concurrency_config);
Question 3:
May I ask for the example that splitting the network into two sub-graphs, then setting the first graph → 4 small cores, second graph ->4 big cores. In C++ setting: I should set 4 small CPU as {0,1,2,3}, 4 big CPU as {4, 5, 6, 7} with "tvm::runtime::threading ::Configure(tvm::runtime::threading::ThreadGroup::kSpecify, 0, CPUs, concurrency_config);
But my question is that since I have two sub-graphs, how exactly can use such function to do CPU affinity settings?
Should I call these functions twice?
But the said way to use config_threadpool in python may can not do the multiple runtime cpu affinity setting work, in our full
solution, the c++ runtime library would call "“tvm::runtime::threading ::Configure” in each runtime thread to do the affinity setting and this part logic is transparent to python user at same time python user just need to forward the cpu affinity setting into c++ library.
**Question 2:** What is the meaning of concurrency_config in the following Configure "tvm::runtime::threading ::Configure(tvm::runtime::threading::ThreadGroup::kSpecify, 0, cpus, concurrency_config);
set the cpu affinity for the runtime launched by current thread, “cpus” is the affinity cpu list
Question 3:since I have two sub-graphs, how exactly can use such function to do CPU affinity settings? Should I call these functions twice?
yes if you prefer implement your own runtime, you should create 2 threads and call the said functions in each thread.
I have rebuilt TVM on Jan 28th with version: tvm-0.9.dev423+g6a274af9c-py3.8-linux-aarch64. I also apply this
CPU affinity setting when I building TVM to utilize CPU affinity = -2.
I followed the same setting as you mention in splitting logic python file to split the network into 2 subgraphs and try to run in pipeline format.
I am wondering for the following the setting
Does pipeline.run(True) mean the pipeline module running in sequential mode instead of pipeline format?
The result I got with normal graph_executor (without any pipeline setting): (Using only 4 thread)
Mean inference time (std dev): 1326.98 ms (15.09 ms)
Throughput of inference is : 0.75 batch/sec
The result I got with the current TVM version pipeline module: (Using only 4 thread)
Mean inference time (std dev): 1318.96 ms (9.06 ms)
Throughput of inference is : 0.76 batch/sec
The result I got with the previous TVM version pipeline module: (Using 8 thread)
Throughput of inference: it would totally different than 0.76 batch/sec.
If so, may I ask how can I run them in the pipeline format?
Or if It’s not implemented/supported yet, may I ask what’s the timeline to add pipeline executing into the current TVM?
Does pipeline.run(True) mean the pipeline module running in sequential mode instead of pipeline format?
Yes, currently Pipeline executor still in the process of upstreaming, and only support sequential mode.
If so, may I ask how can I run them in the pipeline format? Or if It’s not implemented/supported yet, may I ask what’s the timeline to add pipeline executing into the current TVM?
Like what I mentioned in before comments, to try the pipeline executor feature please wait for the whole upstream getting done, about the timeline, as a rough prediction it may still need one or two month for all of the rest patches, and please refer related tracking issue
(https://github.com/apache/tvm/issues/8596) for the progress.
Thanks for your answer, I will keep an eye on your tracking progress.
For my previous inference evaluations, I built and extended my pipeline executor upon this previous PR #7892 (I know it’s outdated now and already closed) and split networks into 2 subgraphs, then running 2 subgraphs in pipeline mode with “pipeline.run()”.
I used “htop” to check CPU utilization and I could see 8 threads running now and CPU utilization 800% (which means all CPU resources are being utilized) and higher throughput, so I think these subgraphs are indeed running in pipeline format.
May I double-check for those results, are they still legit?
@popojames , I guess your questions is that you get same throughput by using latest TVM as enabling subgraph pipeline, is that normal? the answer is ‘YES’ for that the ‘parallel feature’ still on the way to upstreaming. hopefully this answered your question, and Happy Lunar new year
@hjiang
Thanks for your answer.
I understand for the latest TVM, I will get the same result as normal inference (without pipeline).
Maybe I didn’t make my question clear enough.
In TVM dev0.8 version,
I think function “pipeline.run()”, this version is with enable running in pipeline mode.
My question is that are the results obtained from pipeline.run() in PR7892 reliable?
I think function “pipeline.run()”, this version is with enable running in pipeline mode. My question is that are the results obtained from pipeline.run() in PR7892 reliable?
the PR #7892 is a closed PR, you can do some try on this PR, but we highly recommend you to wait and use the official TVM subgraph pipe feature after all upstreaming done, as we will not sustain the said closed PR7892.
I was able to pin the desired CPU affinity successfully.
For example, the following code means the model is only running on two big cores (and using core 6 and 7).
Following the same logic, and according to your previous answer,
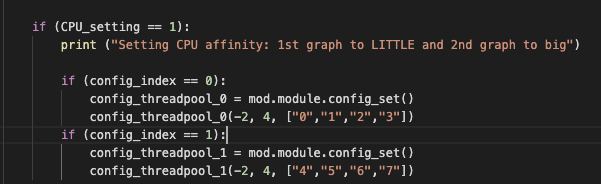
I create two threads for two sub-graphs with setting 1st graph to LITTLE and 2nd graph to big. Here is the code:
wherein, config_threadpool_0 is CPU affinity controller for subgraph_0 and
config_threadpool_1 is CPU affinity controller for subgraph_1
However, I found out with this setting, if two thread_config is set, only the second one would be updated. In other words, the setting in the figure would make subgraph_1 running on 4 big cores, and subgraph_0 is not activated and running on default mode (which is 4 big cores).
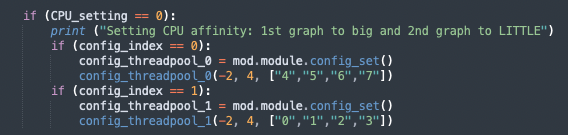
As for another setting with 1st graph to big and 2nd graph to LITTLE,
Here, subgraph_1 running on 4 small cores and subgraph_0 will run with default setting (which is 4 big cores). Although this second setting fulfills what I wanna do, the overall setting is somehow inflexible and hard to use.
May I ask do you have any comment on that or do you have a better way to create threads and set CPU affinity in python simulation?