Hey,
I’m trying to deploy a module using the c++ runtime and cuda. The module I’m struggling with is the pretrained version of yolov8m (which works just fine in the python wrapper for the tvm runtime). For c++ deployment I based my code on ~/apps/howto_deploy’s c++ example (see code at the bottom). I’m running WSL on Windows, therefore libcuda.so is stubbed at /usr/local/cuda/lib64/stubs.
Ubuntu 20.04, NVIDIA driver 537.58 (Windows), CUDA 12.2, tvm: 0.17.dev0, llvm: 18.1.7
The input ndarray seems to not be allocated on GPU because I get a seg fault while writing to index 0.
log:

gdb:

When I change the device from kDLCUDA to kDLCUDAHost, I don’t get the seg faults but encounter another problem. Tbh, I’m not sure which device I’m supposed to use with a dedicated GPU (RTX 4050). Examples/tutorials seem to be rather mobile and CPU focused. kDLCUDAHost error as follows:
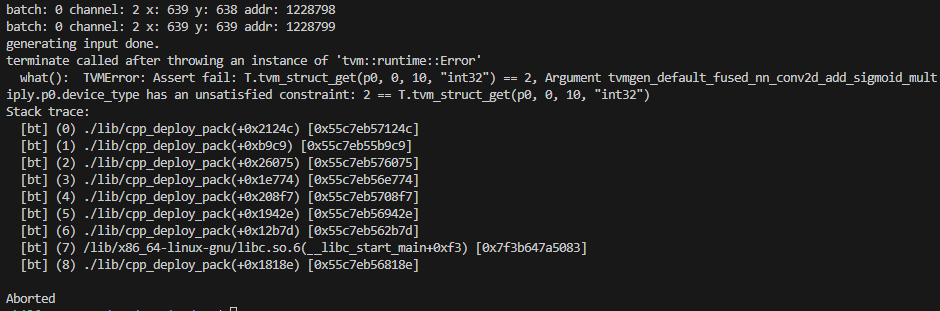
Hints or relevant reading material are greatly appreciated!
Thanks,
~phil
Code
cpp.deploy.cc:
#include <dlpack/dlpack.h>
#include <tvm/runtime/module.h>
#include <tvm/runtime/packed_func.h>
#include <tvm/runtime/registry.h>
#include <cstdio>
void DeployGraphExecutor() {
LOG(INFO) << "Running graph executor...";
// load in the library
DLDevice dev{kDLCUDA, 0};
tvm::runtime::Module mod_factory = tvm::runtime::Module::LoadFromFile("lib_4050.so");
// create the graph executor module
tvm::runtime::Module gmod = mod_factory.GetFunction("default")(dev);
tvm::runtime::PackedFunc set_input = gmod.GetFunction("set_input");
tvm::runtime::PackedFunc get_output = gmod.GetFunction("get_output");
tvm::runtime::PackedFunc run = gmod.GetFunction("run");
// Use the C++ API
tvm::runtime::NDArray input = tvm::runtime::NDArray::Empty({1, 3, 640, 640}, DLDataType{kDLFloat, 32, 1}, dev);
tvm::runtime::NDArray output = tvm::runtime::NDArray::Empty({1, 84, 8400}, DLDataType{kDLFloat, 32, 1}, dev);
const u_int32_t input_values_in_x = 640;
const u_int32_t input_values_in_channel = 640*input_values_in_x;
const u_int32_t input_values_in_batch = 3*input_values_in_channel;
for (int b=0; b<1; b++) {
// batch
for (int c=0; c<3; c++) {
// channel
for (int x=0; x<640; x++) {
// x
for (int y=0; y<640; y++) {
// y
u_int32_t index = b*input_values_in_batch + c*input_values_in_channel + x*input_values_in_x + y;
printf("batch: %i channel: %i x: %i y: %i addr: %i\n", b, c, x, y, index);
static_cast<float*>(input->data)[index] = static_cast <float> (rand()) / static_cast <float> (RAND_MAX);
}
}
}
}
printf("generating input done.\n");
set_input("input0", input);
run();
get_output(0, output);
const u_int32_t values_in_class = 8400;
const u_int32_t values_in_batch = 84*values_in_class;
u_int8_t highest_pred_class = 0;
float highest_pred_conf = 0;
for (int b=0; b<1; b++) {
// batch
for (int c=0; c<84; c++) {
// class
for (int p=0; p<8400; p++) {
// prediction
float current_prediction = static_cast<float*>(output->data)[b*values_in_batch + c*values_in_class + p];
if (current_prediction > highest_pred_conf) {
highest_pred_conf = current_prediction;
highest_pred_class = c;
}
}
}
}
printf("highest prediction: %i (%f)\n", highest_pred_class, highest_pred_conf);
}
int main(void) {
DeployGraphExecutor();
return 0;
}
Makefile:
TVM_ROOT=/home/phil/tvm
DMLC_CORE=${TVM_ROOT}/3rdparty/dmlc-core
PKG_CFLAGS = -std=c++17 -O2 -g -fPIC\
-I${TVM_ROOT}/include\
-I${DMLC_CORE}/include\
-I${TVM_ROOT}/3rdparty/dlpack/include\
-I/usr/local/cuda/include
PKG_LDFLAGS = -L${TVM_ROOT}/build -ldl -pthread -L/usr/local/cuda/lib64 -L/usr/local/cuda/lib64/stubs -lcuda -lcudart
.PHONY: clean all
all:lib/libtvm_runtime_pack.o lib/cpp_deploy_pack
# Build rule for all in one TVM package library
.PHONY: lib/libtvm_runtime_pack.o
lib/libtvm_runtime_pack.o: tvm_runtime_pack.cc
@mkdir -p $(@D)
$(CXX) -c $(PKG_CFLAGS) -o $@ $^ $(PKG_LDFLAGS)
# Deploy using the all in one TVM package library
.PHONY: lib/cpp_deploy_pack
lib/cpp_deploy_pack: cpp_deploy.cc lib/libtvm_runtime_pack.o
@mkdir -p $(@D)
$(CXX) $(PKG_CFLAGS) -o $@ $^ $(PKG_LDFLAGS)