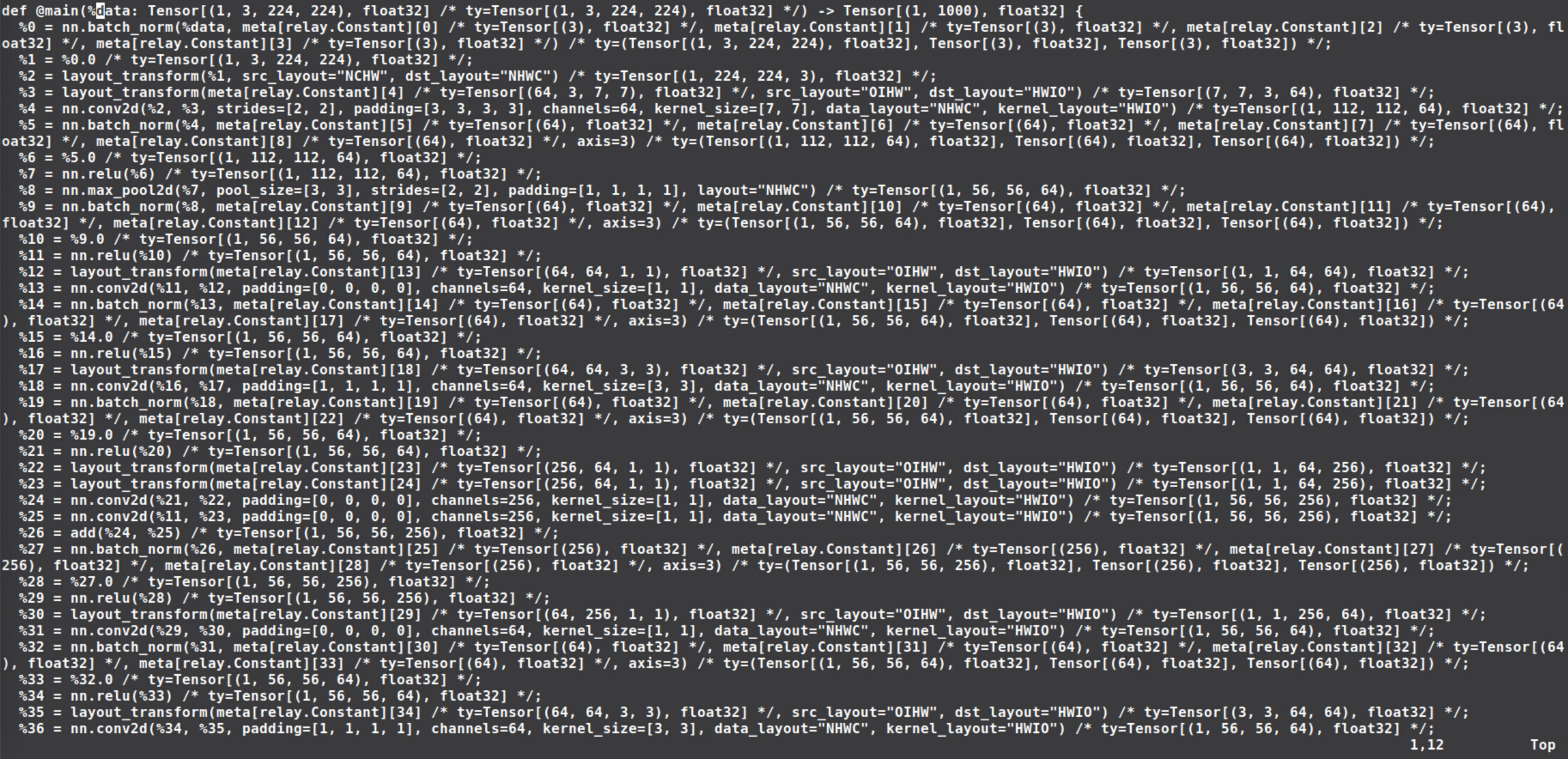
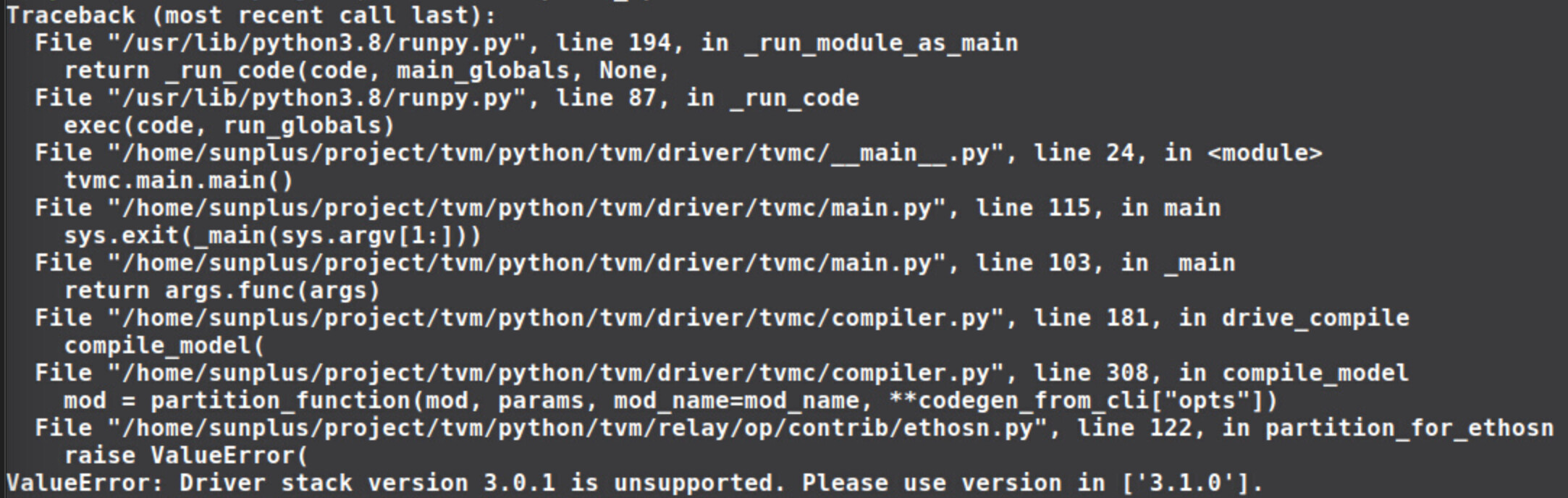
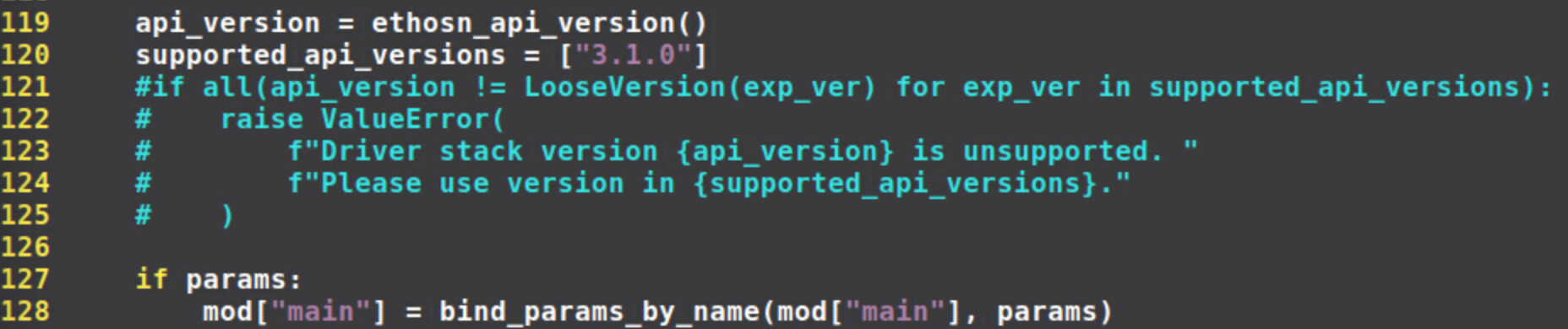
Thanks a lot. After these tips, I could run with ethosn and llvm. Rather, after I saw the graph.json from the module.tar, I found there is no computing operator using ethos-n. I think that is because of the model I used, I should change a model to test for my ethos-n. Is that right?
Here is my code which can run successfully.

Here is the model I used now: https://github.com/onnx/models/raw/b9a54e89508f101a1611cd64f4ef56b9cb62c7cf/vision/classification/resnet/model/resnet50-v2-7.onnx