I have tried using CPU and NPU to run mobilenet_v2. After annotating, NPU would run nn.reshape and nn.avg_pool2d and qnn.add. Unfortunately, the output was incorrect(I have tried 50 pictures for test). Nevertheless, after I commented the line which annotates nn.avg_pool2d as follows, the output is correct.
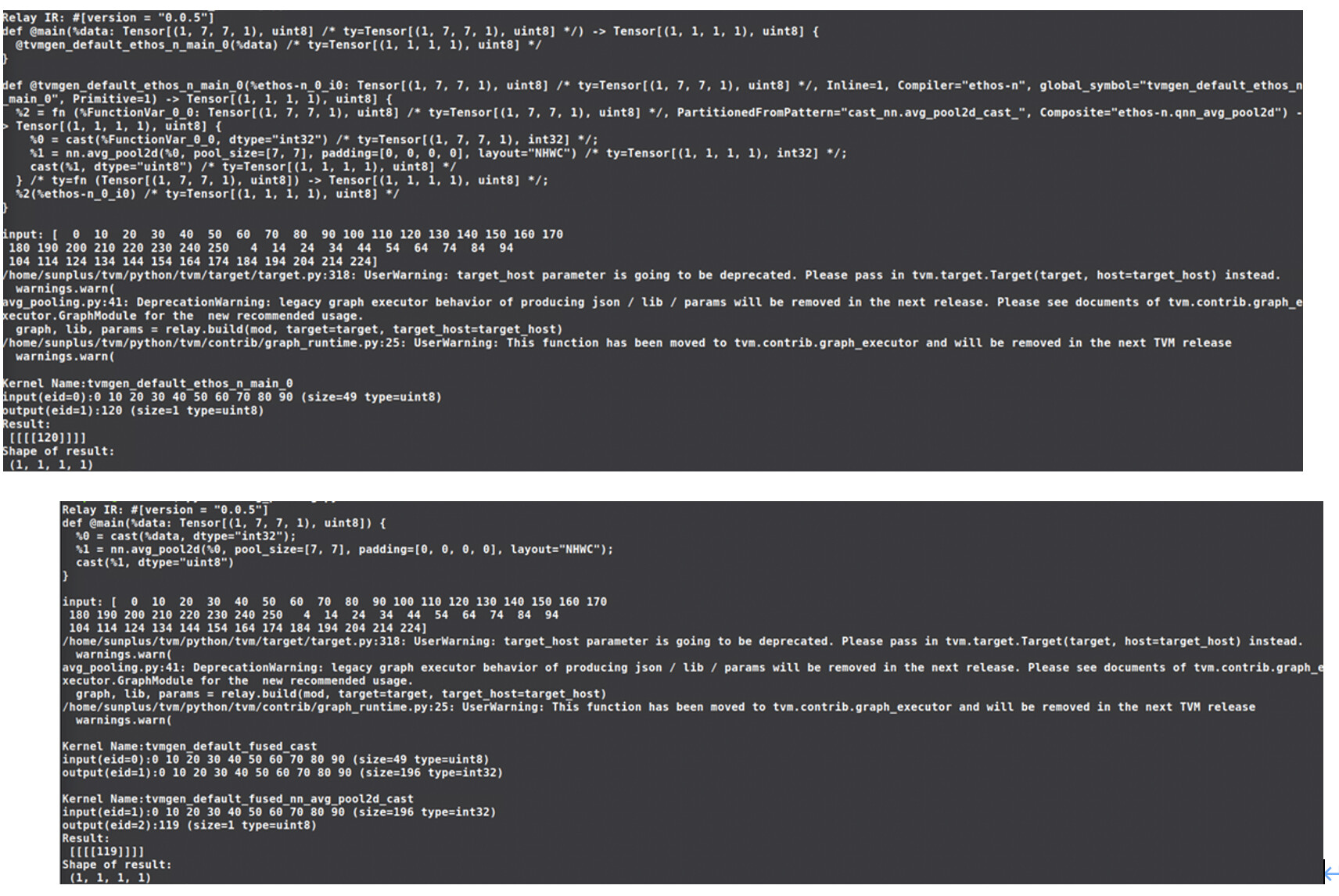
I have also tried to just run one “cast+avg_pool2d+cast” operator on npu, and the result is different from the result created by cpu.
Besides, I have tried using CPU and NPU to run resnet50, but I even cannot compile it. After I called the instructions lib.export_library, it starts to compile the source code using g++, and finally I got the results: g++: fatal error: Killed signal terminated program cc1plus. compilation terminated.
@lhutton1 might be able to help?
Hi @guanjen375, I’ll be happy to look into this for you, could you share the Relay input for the cast+avg_pool2d+cast operator?
We do have a test to check compilation for resnet50, could you confirm if this is the same network you’re trying to compile for, or whether there is a different variation you’re using? https://github.com/apache/tvm/blob/1b9e20a807e7bfa369755822342b8830b853fa86/tests/python/contrib/test_ethosn/test_networks.py#L140
The relay and the output is as follows: (The Result is just the average of all values)
(0+10+20+30+40+50+60+70+80+90+100+110+120+130+140+150+160+170+
180+190+200+210+220+230+240+250+4+14+24+34+44+54+64+74+84+94+
104+114+124+134+144+154+164+174+184+194+204+214+224)/49 = 119.6.
The cpu gives the result 119 while the npu gives the result 120.
Besides, what the compilation fail means as follows:
Here is my source code:
import tvm
import ssl
from tvm.relay.op.contrib import get_pattern_table
target = 'c'
target_host = 'c'
ctx = tvm.cpu(0)
input_name = 'input_1'
model_path = './resnet/resnet50_uint8_tf2.1_20200911_quant.tflite'
data_type = 'float32' # input's data type
batch_size = 1
num_class = 1000
image_dimention = 3
image_shape = (224, 224)
data_shape = (batch_size,) + image_shape + (image_dimention,)
out_shape = (batch_size, num_class)
import os
tflite_model_file = os.path.join(model_path)
tflite_model_buf = open(tflite_model_file, "rb").read()
try:
import tflite
tflite_model = tflite.Model.GetRootAsModel(tflite_model_buf, 0)
except AttributeError:
import tflite.Model
tflite_model = tflite.Model.Model.GetRootAsModel(tflite_model_buf, 0)
import tvm.relay as relay
dtype_dict = {input_name: data_type}
shape_dict = {input_name: data_shape}
mod, params = relay.frontend.from_tflite(tflite_model,shape_dict=shape_dict,dtype_dict=dtype_dict)
pattern = get_pattern_table("ethos-n")
mod = relay.transform.InferType()(mod)
mod = relay.transform.MergeComposite(pattern)(mod)
mod = relay.transform.InferType()(mod)
mod = relay.transform.AnnotateTarget("ethos-n")(mod)
mod = relay.transform.InferType()(mod)
mod = relay.transform.MergeCompilerRegions()(mod)
mod = relay.transform.InferType()(mod)
mod = relay.transform.PartitionGraph()(mod)
from tvm.relay.expr_functor import ExprMutator
with tvm.transform.PassContext(opt_level=3, config={"tir.disable_vectorize":True}):
graph, lib, params = relay.build(mod, target=target, target_host=target_host, params=params)
lib.export_library('./lib.so')
I just tried to run this code and get the result of compilation failed.
Sometimes the machine will even crash because of the compilation.
Thanks @guanjen375,
To answer the question about average pool, a difference of 1 can be expected. This is because TVM’s schedules can apply slightly different rounding when compared to the NPU for quantized types. In fact, all of our operator tests are compared within a tolerance of 1 for this reason e.g. for average pool see: https://github.com/apache/tvm/blob/main/tests/python/contrib/test_ethosn/test_pooling.py#L68.
For resnet, thanks for sending the example across. Without seeing the uint8 variant of resnet you seem to be using I can’t say for sure what the issue is, but I’ll try to offer some suggestions. When loading a model using the from_tflite mechanism, parameters (constants) are not bound to the module and are instead treated similar to a variable input. The partitioning relies on these parameters being bound to the main function for pattern matching to work as intended, but in your example this isn’t the case. I’d recommend taking a look at my suggestion here: Constant params should be constants - #3 by lhutton1, and applying it before running the merge composite pass.
Alternatively (and perhaps a more elegant approach), is that we have a convenient function that manages the partitioning pipeline called partition_for_ethosn(...). I’d suggest using this rather than building your own pipeline as it allows us to add more optimization passes to the partitioning in the future. It could be dropped into your example similar to:
from tvm.relay.op.contrib.ethosn import partition_for_ethosn
mod, params = relay.frontend.from_tflite(model, shape_dict, dtype_dict)
mod = partition_for_ethosn(mod, params, variant="n78")
with tvm.transform.PassContext(...):
relay.build(...)
Note: I didn’t run this snippet, but hopefully it’s enough to get you started 
It seems with your current example not many operations will be partitioned for the NPU and instead run on the CPU, so it might be the case that the segfault comes within this lowering process towards CPU.
Hope this helps!
Edit: I would also recommend taking a look at the user-facing TVMC Python interface, which should automatically take care of these types of issues.
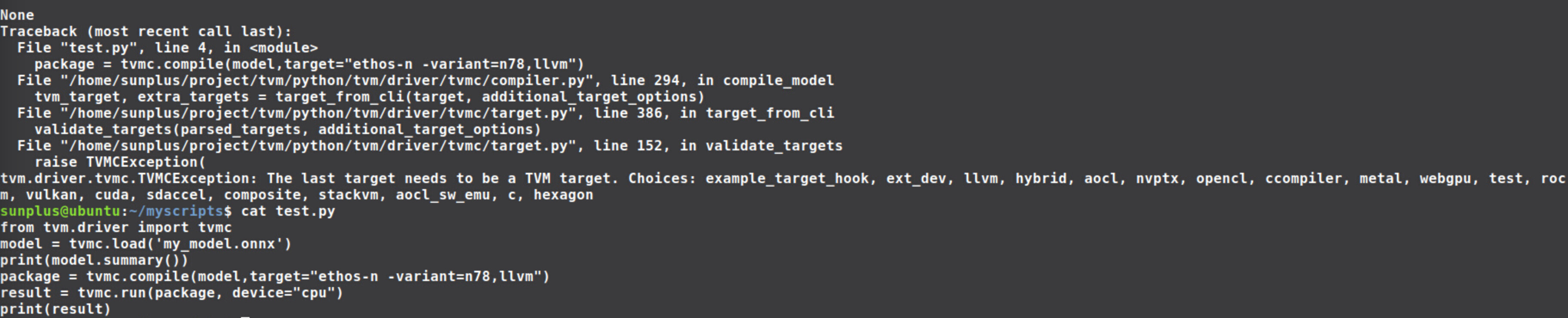
Thanks for your help. I have tried the tvmc yesterday and run on CPU successfully.
Here is my code using tvmc:
from tvm.driver import tvmc
model = tvmc.load('my_model.onnx')
print(model.summary())
package = tvmc.compile(model,target="llvm")
result = tvmc.run(package, device="cpu")
print(result)
The result is as follows:
I ran with cpu successfully. Rather,
- I want to run on cpu plus npu and check if I use both of two devices from relay
- I want to to show the result to check if the result is correct.
How should I modify my code to achieve?
This is first time I used the tvmc and have no experience before.
Is there anything I can refer to?
Unfortunately there is no tutorial at the moment for using the NPU via TVMC, although it shouldn’t require too much modification based on what you currently have. I’ll try to answer your immediate questions here.
The target string would need updating to mention the NPU ethos-n -variant=n78 ..., llvm ....
To check that both devices are being used, I usually check how the Relay module was partitioned. In tvmc.compile you can add the options: dump_code="relay" to dump the Relay graph after partitioning and package_path="module.tar" to make sure the package is exported to a known location. The partitioned Relay will then be available in module.tar.relay which can be viewed by a text editor.
Finally, the outputs are available in result.outputs.
Hope this helps
I am not really sure how to modify my code:
Here is my modification which get fails
from tvm.driver import tvmc
model = tvmc.load('my_model.onnx')
print(model.summary())
package = tvmc.compile(model,target="ethos-n -variant=n78,llvm",dump_code=relay,package_path = "module.tar")
result = tvmc.run(package, device="cpu")
print(result.outputs)
Besides, after looking other resources, I found that tvmc is mainly used for command-line execution, is that right?
Hi @guanjen375,
Besides, after looking other resources, I found that tvmc is mainly used for command-line execution, is that right?
Yep that was the original intended use-case, however, the python interface is just as useful IMO and avoids needing to write a lot of boilerplate.
Just looking at your example, I couldn’t spot anything obviously wrong. Would you be able to share the error you’re getting?
Thanks, I tried out your example and the issue is very subtle indeed! You should use ethos-n -variant=n78, llvm rather than ethos-n -variant=n78,llvm (note the space after the comma before llvm). In your example the target string is parsing llvm as an attribute of -variant rather than as a separate target which is what we desire. I wasn’t actually fully aware of this difference until now.
Also, in my previous message I suggested using dump_code=relay. I’ve just realized this should have read dump_code="relay" - I’ll amend above to avoid future confusion.
I believe it should work after these changes.
Thanks a lot. After these tips, I could run with ethosn and llvm. Rather, after I saw the graph.json from the module.tar, I found there is no computing operator using ethos-n. I think that is because of the model I used, I should change a model to test for my ethos-n. Is that right?
Here is my code which can run successfully.
Here is the model I used now:
https://github.com/onnx/models/raw/b9a54e89508f101a1611cd64f4ef56b9cb62c7cf/vision/classification/resnet/model/resnet50-v2-7.onnx
Hi, yes it looks like the model you’re using is in NCHW format which is not supported. You could try to convert the model to NHWC by adding desired_layout="NHWC" to the compile function. This should insert layout_transform operations where necessary so that the graph can be offloaded to the NPU.
I have used several different codes for testing. Rather, I found I have never used ethos-n for running.
My code is as follows:
from tvm.driver import tvmc
model = tvmc.load('my_model.onnx')
print(model.summary())
package = tvmc.compile(model,target="ethos-n -variant=n78, llvm",dump_code="relay",package_path = "module.tar",desired_layout="NHWC")
result = tvmc.run(package, device="cpu")
print(result.outputs)
The output relay graph is as follow(part):(I found there is no use for ethos-n)
-
My Ethos-n is at /dev/ethosn0. I found tvmc.run did not run it anymore.
(I found even I deleted /dev/ethosn0, the runtime executes withour error message)
-
Everytime I tested for the model, I got the different result.
Apologies for missing this before, it looks like the graph you’re providing is in float32 format. Only int8 and uint8 formats can be offloaded to the NPU, so this explains why no operations are being offloaded
Thanks a lot. I will test for other model now.
I have tested my mobilenet model for cpu and cpu+npu using tvmc, but the result is still failed.
(Not the same between cpu and cpu+npu)
My code is here: https://github.com/guanjen375/EthosN-tvmc
By running run_llvm.sh, you can run the mobilenet model with cpu. (target = “llvm”)
By running run_ethosn.sh, you can run the mobilenet model with cpu and npu. (target = "ethos-n -variant=n78, “llvm”)
The result is also shown when running. You can see two result is different.
How should I do to make it consistent ?
Thanks @guanjen375, I believe I was able to reproduce the mismatch: 232 vs 231, 1 vs 2? This can simply be attributed to differences in rounding behaviour of both the LLVM backend and the NPU integration
What you mean is as follows:
cpu result : [[0 0 231 … 0 0 0]] (source run_llvm.sh)
cpu+npu result : [[0 0 232 … 0 0 0]] (source run_ethosn.sh)
Is that right?
Here is my result:
cpu result : [[0 0 231 … 0 0 0]
npu result : [[0 0 0 … 0 0 0]]
If what is correct above, can you provide the tvm edition you use and npu library edition?
Yes that’s correct, your first example is what I got when running the provided scripts. I’m using the latest main f2a740331f21106787a29566185d8924e5dcb25a and the NPU driver stack version 22.08.
It seems as though something could be incorrect with your setup. Just to confirm, does this occur with other networks/operators as well or just the network you’re trying here (mobilenet v2)? It might be worth trying out just the average pool you tested previously to make sure that gives the expected result.