Hi, I created a test pytorch quantized model, The structure is as follows:
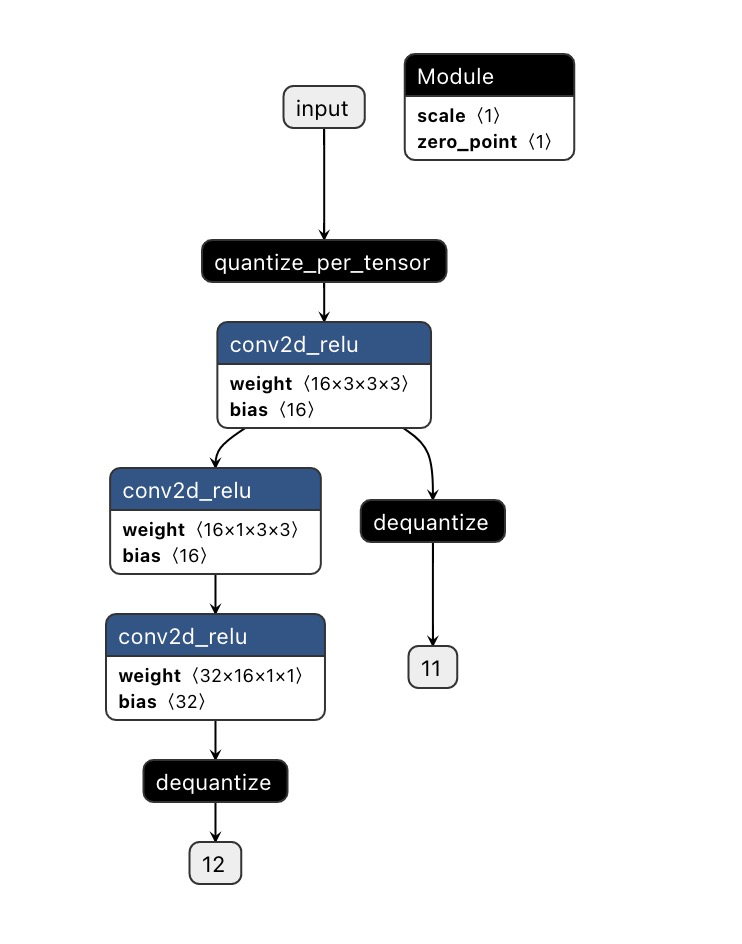
There are 2 dequantize nodes which operate with different scale and zero_point, When I import using tvm the relay ir is as follows:
%0 = qnn.quantize(%input, 0.004226f, 10, out_dtype="uint8", axis=1);
%1 = nn.pad(%0, pad_value=10f, pad_width=[[0, 0], [0, 0], [1, 1], [1, 1]]);
%2 = qnn.conv2d(%1, %backbone.conv1.conv_weight, 10, 0, 0.004226f, 0.0889414f, strides=[2, 2], padding=[0, 0, 0, 0], channels=16, kernel_size=[3, 3], out_dtype="int32");
%3 = nn.bias_add(%2, %backbone.conv1.conv_bias);
%4 = qnn.requantize(%3, 0.000375866f, 0, 0.0899963f, 0, axis=1, out_dtype="int32");
%5 = clip(%4, a_min=0f, a_max=255f);
%6 = cast(%5, dtype="uint8");
%7 = nn.pad(%6, pad_width=[[0, 0], [0, 0], [1, 1], [1, 1]]);
%8 = qnn.conv2d(%7, %backbone.conv2.depth_wise.conv_weight, 0, 0, 0.0899963f, 0.0203802f, padding=[0, 0, 0, 0], groups=16, channels=16, kernel_size=[3, 3], out_dtype="int32");
%9 = nn.bias_add(%8, %backbone.conv2.depth_wise.conv_bias);
%10 = qnn.requantize(%9, 0.00183414f, 0, 0.123625f, 0, axis=1, out_dtype="int32");
%11 = clip(%10, a_min=0f, a_max=255f);
%12 = cast(%11, dtype="uint8");
%13 = qnn.conv2d(%12, %backbone.conv2.point_wise.conv_weight, 0, 0, 0.123625f, 0.00762315f, padding=[0, 0, 0, 0], channels=32, kernel_size=[1, 1], out_dtype="int32");
%14 = nn.bias_add(%13, %backbone.conv2.point_wise.conv_bias);
%15 = qnn.requantize(%14, 0.000942414f, 0, 0.0926806f, 0, axis=1, out_dtype="int32");
%16 = clip(%15, a_min=0f, a_max=255f);
%17 = cast(%16, dtype="uint8");
%18 = (%6, %17);
%19 = %18.0;
%20 = qnn.dequantize(%19, 0.0899963f, 0);
%21 = %18.1;
%22 = qnn.dequantize(%21, 0.0899963f, 0);
(%20, %22)
How are the scales of the two dequantize nodes in relay ir the same? Is this a bug?