
TE allows multiple IterVars on one attaching path (i.e. two nested loops) binding to one thread IterVar. It seems necessary for some schedules that model stages having different thread allocation to have correct bounds to be inferred. These schedules certainly represent valid and useful use cases. However, binding two IterVars on one path to one thread looks unnatural in a schedule tree.
A schedule tree is just another way to represent a loop nest. Binding an IterVar to a threadIdx is replacing a loop with one dimension of thread launch bound and moving the loop up to the host/device boundary. Binding two IterVars on two different attaching paths to the same threadIdx moves both loops up their hierarchies independently, merges them when they meet, and keeps moving up to be part of the launch bound. Both cases are well explained with loop nest manipulation. However, binding two IterVars on one path to the same threadIdx is difficult to explain with loop nest manipulation – two nested loops becomes one via neither fusion nor unrolling, before moving up the hierarchy to be a launch bound.
I feel I miss something here.
The following example is from tests/python/unittest/test_te_schedule_bound_inference.py, a schedule for a 1024x1024 by 1024x204 matrix multiplication in three stages with 256 blocks and 64 threads per block. Threads in a block are allocated in two ways:
- each thread loads 1 data from each input matrix to shared memory in iteration in A.shared and B.shared, respectively;
- each thread is responsible for a 8x8 tile in the output matrix, doing multiplication and accumulation on local memory in CC.local stage and storing result to global memory in CC stage;
In the TE schedule (shown in the tree below), two highlighted IterVars on the same attaching path bind to threadIdx.x. Same situation happens to the path from B.shared and threadIdx.y.
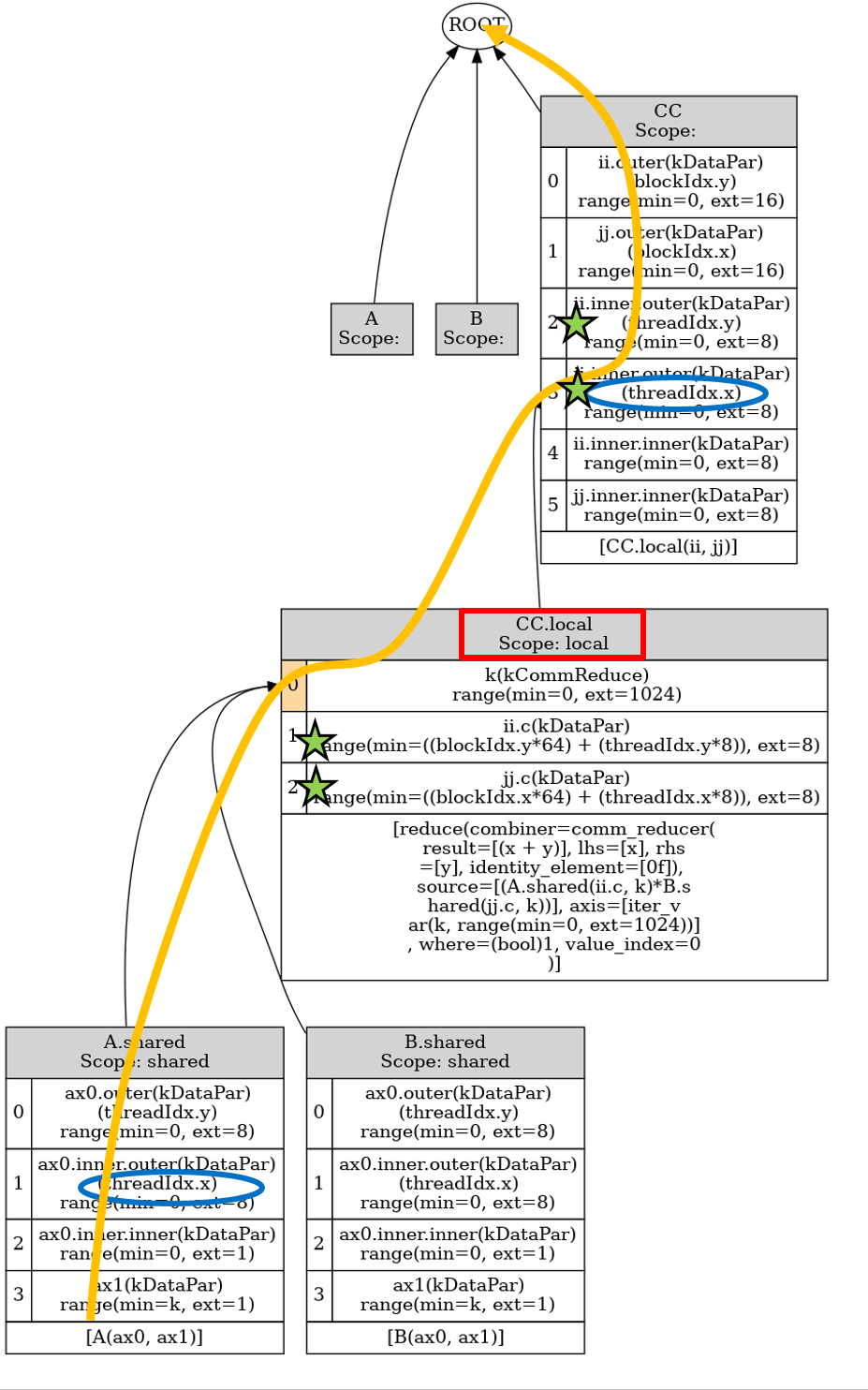
I need to modify the schedule to the tree below to explain it with loop manipulation. This schedule however is not supported by current TE, generating wrong code. The problem comes from bound inference. In order to achieve the desired code, the four IterVars with green stars must relax in both schedule trees. It seems that the two IterVars in stage CC have to be on attaching path to be relaxed for A.shared’s bounds in the current TE implementation, because InferRootBound checks IterVars for relaxation only in two conditions: (i) IterVars in the consumer stages (CC is not A.shared’s immediate consumer in this case) and (ii) IterVars on A.shared’s attaching path (the two IterVars are not in the modified schedule tree).
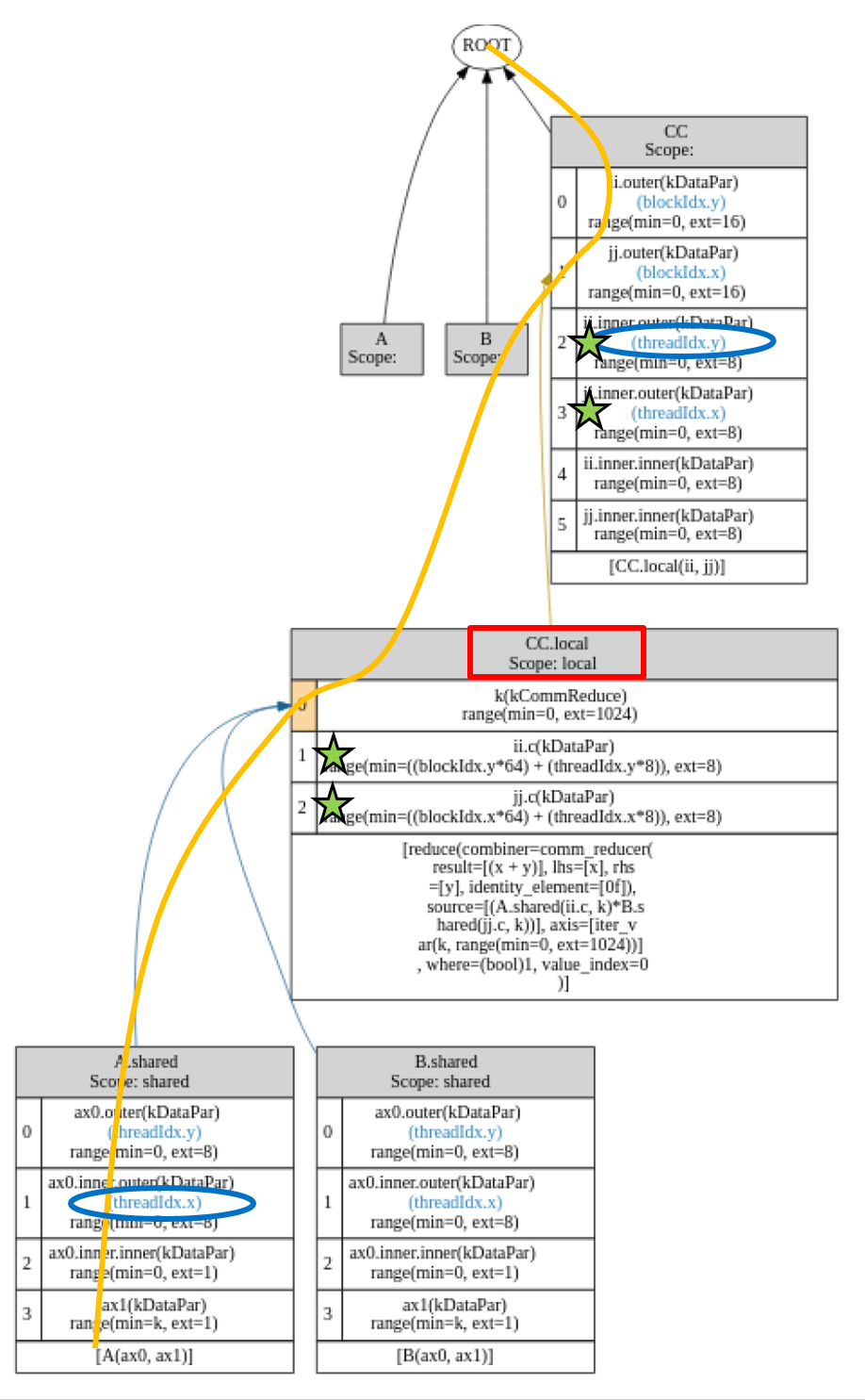
After I modify InferRootBound to check all downstream stages’ IterVars for relaxation, the modified schedule tree generates the same desired code as the one having two IterVars on one path binding to the same threadIdx.
My question is whether allowing binding two IterVars on one attaching path to the same threadIdx is necessary. There might be other use cases that I am not aware of. Please share them with me. If it is not necessary, but still a language feature, I would also like to have a better understanding.
The following code generates the above schedule trees. Notice there are two lines to switch between them.
import tvm
from tvm import te
import numpy as np
import time
nn = 1024
n = tvm.runtime.convert(nn)
A = te.placeholder((n, n), name='A')
B = te.placeholder((n, n), name='B')
k = te.reduce_axis((0, n), name='k')
C = te.compute(
(n, n),
lambda ii, jj: te.sum(A[ii, k] * B[jj, k], axis=k),
name='CC')
# schedule
s = te.create_schedule(C.op)
xtile, ytile = 32, 32
scale = 8
num_thread = 8
block_factor = scale * num_thread
block_x = te.thread_axis("blockIdx.x")
thread_x = te.thread_axis("threadIdx.x")
block_y = te.thread_axis("blockIdx.y")
thread_y = te.thread_axis("threadIdx.y")
CC = s.cache_write(C, "local")
AA = s.cache_read(A, "shared", [CC])
BB = s.cache_read(B, "shared", [CC])
by, yi = s[C].split(C.op.axis[0], factor=block_factor)
bx, xi = s[C].split(C.op.axis[1], factor=block_factor)
s[C].reorder(by, bx, yi, xi)
s[C].bind(by, block_y)
s[C].bind(bx, block_x)
ty, yi = s[C].split(yi, nparts=num_thread)
tx, xi = s[C].split(xi, nparts=num_thread)
s[C].reorder(ty, tx, yi, xi)
s[C].bind(ty, thread_y)
s[C].bind(tx, thread_x)
yo, xo = CC.op.axis
s[CC].reorder(k, yo, xo)
# Switch for the two schedule trees starts here
s[CC].compute_at(s[C], tx) # generate the first schedule tree
# s[CC].compute_at(s[C], bx) # generate the second schedule tree
# Switch for the two schedule trees ends here
s[AA].compute_at(s[CC], k)
s[BB].compute_at(s[CC], k)
ty, xi = s[AA].split(s[AA].op.axis[0], nparts=num_thread)
tx, xi = s[AA].split(xi, nparts=num_thread)
s[AA].bind(ty, thread_y)
s[AA].bind(tx, thread_x)
ty, xi = s[BB].split(s[BB].op.axis[0], nparts=num_thread)
tx, xi = s[BB].split(xi, nparts=num_thread)
s[BB].bind(ty, thread_y)
s[BB].bind(tx, thread_x)
ctx = tvm.context("cuda", 0)
func = tvm.build(s, [A, B, C], target="cuda", name='tid')
assert func
print(func.imported_modules[0].get_source())
from tvm.contrib import tedd
tedd.viz_dataflow_graph(s, False, '/tmp/dfg.dot')
tedd.viz_schedule_tree(s, False, '/tmp/scheduletree.dot')
tedd.viz_itervar_relationship_graph(s, False, '/tmp/itervar.dot')
# Random generated tensor for testing
dtype = "float32"
a = tvm.nd.array(np.random.rand(A.shape[0].value, A.shape[1].value).astype(dtype), ctx)
b = tvm.nd.array(np.random.rand(B.shape[0].value, B.shape[1].value).astype(dtype), ctx)
c = tvm.nd.array(np.random.rand(C.shape[0].value, C.shape[1].value).astype(dtype), ctx)
func(a, b, c)
result = c.asnumpy()
answer = np.matmul(a.asnumpy(), b.asnumpy().transpose())
tvm.testing.assert_allclose(result, answer, rtol=1e-2)