Yes, I just changed the target from llvm to llvm -mcpu=core-avx2, and use module.time_evaluate("run", ctx, 100) to timing the latency. Below is my python code:
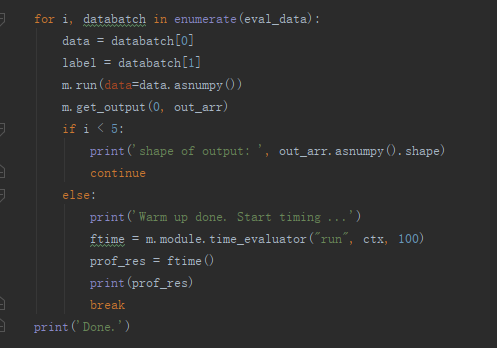
the batch size is 1, the first 5 batch is used to warm up the graph. I wonder can I add a synchronize api before time_evalute() like mx.nd.watiall() in mxnet?