Background: There has been many papers in academic literature on quantizing weight tensors in deep learning models to reduce inference latency and memory footprint. Also, TVM recently gained the ability to quantize weights (https://github.com/dmlc/tvm/pull/2116)
I am currently working on a systematic benchmark for existing frameworks for (post-training) quantization. A rigorous benchmark will help machine learning practitioners make informed decisions. Any suggestions are welcome.
To account for variance due to virtualization and shared hardware, I will perform multiple trials by launching new instance(s). I will perform statistical tests to verify if an apparent difference in a metric is significant or due to chance.
To ensure that we are comparing apples to apples, benchmark code (with links to models used) will be published as a GitHub repository.
@Vinayak618 No, currently TVM does not support reading from quantized TensorFlow models. Here is a proposal for supporting quantized TF-Lite models: https://github.com/dmlc/tvm/issues/2351. For now, you’ll have to load the original (non-quantized) model into TVM and use TVM’s quantization tools to perform quantization.
@hcho3.
Thank you for the response.
Can you guide me from where can i find TVM’s quantization tools to apply it on tensorflow model?
I dint find that in the link above.
Also one query not related to the above issue.
Does opt_level in tensorflow NNVM frontend have any significance after opt_level 3.
I’m getting the results even at opt_level 10 so.
@Vinayak618 I’m trying to figure out TVM’s quantization pass myself, so I won’t be able to guide you right now. I will put up the benchmark code when it’s done, and you can look at it then. For now, you should look at the pull request https://github.com/dmlc/tvm/pull/2116.
And I think opt_level goes only up to 3.
Ps. If you have other questions, please open a new thread. Let’s keep this thread for discussing the benchmark proposal.
Thank you @hcho3.
Yeah sure will keep it for discussing benchmark proposal.
Once you are done with benchmark code. Please put up the same in this thread. In the mean time ill go through the pull request.
We are currently working on some enhancements to quantization on the TVM side, as some models (DenseNet, MobileNet) need per-channel quantization scale adjustment to avoid catastrophic accuracy loss.
Another issue is that models that use depthwise convolution such as mobilenet will currently see limited speedup vs. floating-point versions because TVM currently lacks schedules for depthwise convolution with NCHWc or NHWC data layouts (preventing vectorization).
Currently the most interesting results will be with Inception and ResNet.
If two consecutive layers are quantized, there is no dequantization-requantization between this (you can check the graph after the realize pass to verify this).
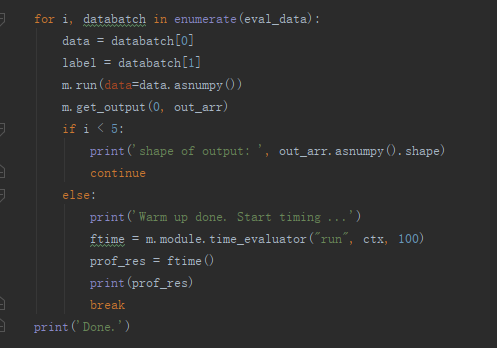
Yes, I just changed the target from llvm to llvm -mcpu=core-avx2, and use module.time_evaluate("run", ctx, 100) to timing the latency. Below is my python code:
the batch size is 1, the first 5 batch is used to warm up the graph. I wonder can I add a synchronize api before time_evalute() like mx.nd.watiall() in mxnet?