Hello, When I use real time classification on camera with none tune. The fps is about 13~14. The network is EfficientNetV2-B0 and I converted ckpt to onnx from official website.https://github.com/google/automl/tree/master/efficientnetv2
In autoscheduler , I set target=‘cuda sm_61’ , ‘n_trial=10000’ ,Fps is become to 0.2~0.3 .Maybe it’s the TVM version is too old,so I reinstall it and I set target=‘cuda sm_61’ , ‘n_trial=5000’,still get the poor performance.
Did I use the wrong way to apply the best result in tuning file?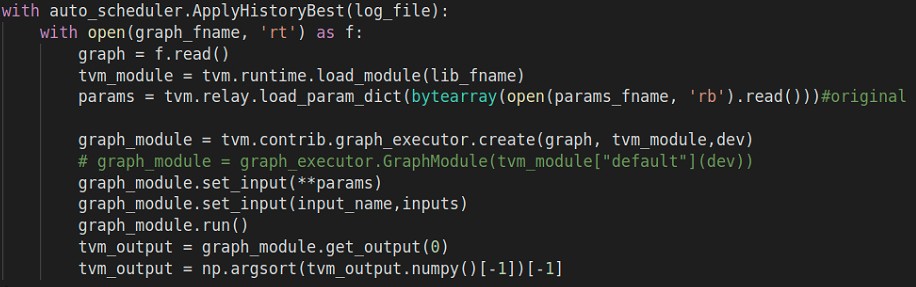
Does anyone have an idea why use autoscheduler is worse than none-autoscheduler?
Thanks!!