Apache TVM.Next Discussion (TVM Unity)
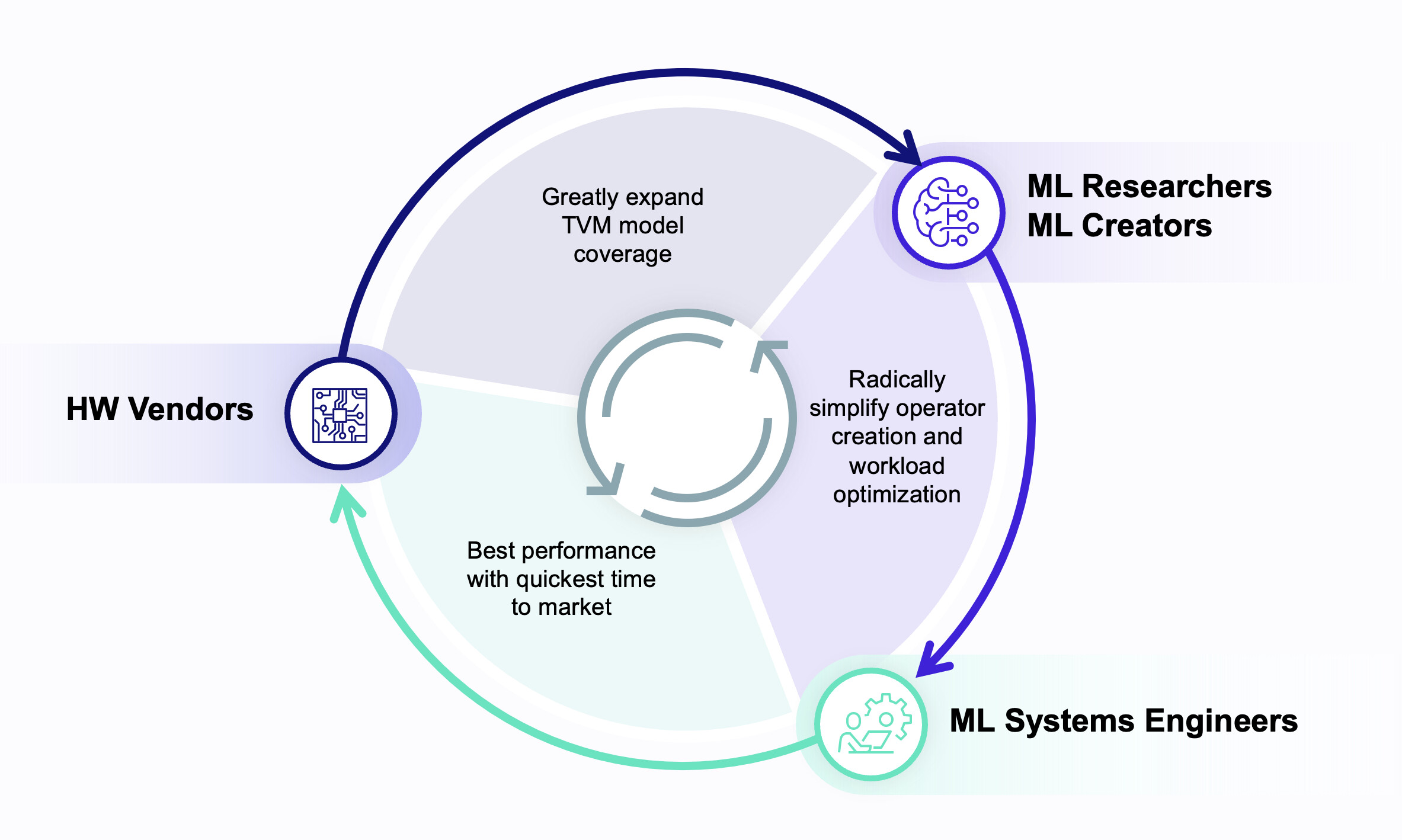
Objective: Strengthening the virtuous circle that connects the ecosystem of ML scientists, ML engineers and hardware vendors fostering greater collaboration amongst them. And in doing so it creates an opportunity to strengthen and grow the Apache TVM community and spur on greater innovation within the TVM project itself.
Technical Challenges with TVM Today
For the ML scientist: TVM remains challenging for ML scientists to use. ML scientists are most interested in designing new operations, or tweaking existing ones to meet a performance or portability goal. Furthermore, they need a clear API which enables them to easily express a large space of operations. Unfortunately, today TVM exposes a limited compute and scheduling API which–although performant and portable–does not always provide the expressivity required to write certain kernels for a desired hardware target. Moreover, ML scientists are not getting what they need, which is an integration into the deep learning framework of their choice without having to understand TVM’s internals.
For the ML engineer: TVM first focused on optimizing the operator graph and individual operations separately, which although profitable in many cases does not always guarantee optimal performance. Achieving the best performance results today requires a mixture of automatic and hand-crafted optimizations across both layers and libraries. Many of these “split” APIs create hard boundaries between the different personas working on deep learning compilation and prevent collaboration.
There are a few barriers today, which prevent the following: mixing different deep learning backends to achieve optimal performance, performing search based optimizations across layers, interpolating between human domain knowledge and full automation, and optimizing emerging training and inference workloads featuring dynamic shapes and ranks, and features such as RNG. The result today is that current abstractions impede blending the best of TVM with the software backends that ML engineers are already running in production.
For the Hardware vendor: How the industry writes kernels and operators and by extension models themselves is highly dependent on the hardware target. And that dependency to the hardware target effectively constrains the model coverage for any hardware provider; be it a market leader or a startup. In order to maximize coverage, end-user abstractions are needed to automatically adapt software to take advantage of a breadth of hardware targets and their respective hardware primitives without end-user effort. Similarly hardware providers desire abstractions which enable new kernels, operators, models to work on both new and existing hardware without constant work per hardware target.
Unity Approach for Better Collaboration Among Our 3 Key Personas
In order to tackle these challenges the community needs common shared infrastructure and APIs which enable these personas to more effectively collaborate. For example, we need to enable ML scientists to build customized operators, which are optimized by domain knowledge from ML engineers and leverage the latest greatest hardware features.
For the ML scientist: TVMscript is an evolution of TVM’s Python scripting language that simplifies the ability to create new high performance kernels with just a few lines of code. At TVMcon, there will be a community example highlighting an innovation that includes a new kernel previously written in PyTorch that can be accelerated. In addition we will see evolving mechanisms for integrating TVM into both training and inference of deep learning frameworks.
For the ML engineer: At TVMcon, there is a desire to share a technical vision which captures both what many parties in the community have been working on for the past year, and sets the stage for next year. The goal is to address the challenges surfaced by the community (and noted above) by providing a shared set of abstractions which enable personas to better collaborate on mixing multiple backends, optimizing across layers, incorporating automation and domain knowledge, and setting the stage for advanced workloads.
TVM community leadership will discuss how the work this year, and the on-going work beyond that will drive us towards a unified set of abstractions. For example, last year the community introduced a mechanism for mixing different compiler backends together known as Bring Your Own Codegen (BYOC). This approach has been useful for ML engineers to leverage TVM’s kernels and optimization techniques, while still connecting with the existing deep learning backends of hardware vendors. Yet, there are still barriers to effectively mixing and matching backends; that is why there is a plan to demonstrate a prototype of an evolutionary step.
TVM community leadership will also present examples that touch on the challenges of cross layer optimization, improving the auto-tuning framework in the form of AutoTIR, and exploratory work on cross layer optimization and emerging workloads. The community is attempting to remove these barriers in 2021 and 2022 to enable stronger collaboration between these different personas.
For the hardware vendor:
The TVM community is demonstrating novel functionality for hardware vendors that makes their solutions more extensible to ML scientists and ML engineers and empowers them to take advantage of novel hardware features found in next generation CPUs, GPUs and NPUs.
For example, the community already has an effort around Auto Tensorization which makes the tensor intrinsics of the hardware provider readily available to kernel and operator creators without them needing to know how to write compiler code for that hardware.
Community
Finally, ApacheTVM PMC members and committers know that growing the project’s technical scope to better serve the virtuous cycle between end-users and hardware vendors is not possible without also growing and adapting the community. We know that in order to do this we must at least make changes including, but not limited to:
- Better mechanisms to change the community structure for PMC members and committers, so we can evolve our process and tooling.
- Better guidelines and standards about how contributors evolve all the way from first time contributors to PMC members.
- Developing a shared public roadmap so that we can better coordinate the diverse set of individuals developing the TVM project.
- Clearer ownership of code areas and consensus processes.
The goal of the below document is to kick off a conversation that starts today, will carry into TVMcon and continue into the new year.
Thanks to the many folks who provided valuable input in constructing this document.