I’m tuning a conv2d workload on Mate30 android phone with Mali G76MP16, below is the compute_dag
========== Task 5 (workload key: ["65de44bf533ab9836cbbb4ede45ac081", 1, 348, 12, 12, 2084, 348, 1, 1, 1, 2084, 1, 1, 1, 2084, 12, 12]) ==========
placeholder = PLACEHOLDER [1, 348, 12, 12]
PadInput(i0, i1, i2, i3) = placeholder[i0, i1, i2, i3]
data_vec(n, h, w, ci, vh, vw) = PadInput[n, ci, ((h*4) + vh), (w + vw)]
placeholder = PLACEHOLDER [2084, 348, 1, 1]
kernel_vec(co, ci, kh, kw, vc) = placeholder[((co*4) + vc), ci, kh, kw]
conv(n, co, h, w, vh, vw, vc) += (data_vec[n, h, w, ci, (vh + kh), (vw + kw)]*kernel_vec[co, ci, kh, kw, vc])
output_unpack(n, co, h, w) = conv[n, floordiv(co, 4), floordiv(h, 4), w, floormod(h, 4), 0, floormod(co, 4)]
placeholder = PLACEHOLDER [1, 2084, 1, 1]
T_add(ax0, ax1, ax2, ax3) = (output_unpack[ax0, ax1, ax2, ax3] + placeholder[ax0, ax1, 0, 0])
T_sigmoid(ax0, ax1, ax2, ax3) = tir.sigmoid(T_add[ax0, ax1, ax2, ax3])
T_multiply(ax0, ax1, ax2, ax3) = (T_add[ax0, ax1, ax2, ax3]*T_sigmoid[ax0, ax1, ax2, ax3])
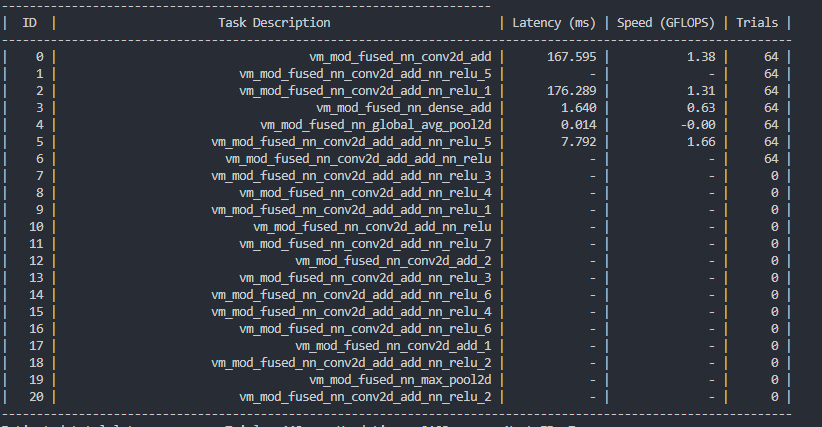
The tuning however yielded impossible perf numbers
----------------------------------------------------------------------
| ID | Latency (ms) | Speed (GFLOPS) | Trials |
-------------------------------------------------
......
| 5 | 0.029 | 7122.14 | 64 |
Only happens on newer Mali models. P30 with Mali G76 MP10 did not encounter such error, but Mate30 with G76 MP16 and Mate40 with G78MP24 both have similar issues.
Thoughts?