
@tqchen Any Methods to debug to know which intermediate layer outputs is not correct. i seach the whole formu, but cant get answer.
Hi there, you can use the debug_executor to get the intermediate results.
You can see details discussed in this forum thread.
You will need to have a ground truth to compare against, depending on what framework your source model is from.
thx, could u give me some concrete example?
Sure, you can see an example of how to use the debug_executor in this part of the docs.
The tensors will be dumped to a file, and you can then load this data using code such as:
data = relay.load_param_dict(bytearray(open("./_tvmdbg_device_CPU_0/output_tensors.params", "rb").read()))
All the tensors will be saved as binary bytes in serialized format. The result binary bytes can be loaded by the API “load_params”.
how can we achive binary bytes in serialized format? does “./_tvmdbg_device_CPU_0/output_tensors.params” contains all layers outputs? then we get data, how to use it to get the exact layer? i still so confused.
You say that the output is not correct, can you provide a reproducible example of what model you are running, and how? Perhaps there is an issue there.
To answer your question, this part of the documentation takes you through how to run the model while saving the intermediate outputs for given input data.
The result of relay.load_param_dict will be a dictionary with the various intermediate outputs. You can look at the names of the tensors to see what layer they are related with, with additional model information being stored in the _tvmdbg_device_CPU_0/ directory.
You can then compare the output of each layer in the dictionary with what you expect it to be.
cause tvm leave no origin network layers infomation in the tvm graph, so how can i use dump data compared with orgin network layers?
for exmaple, the bert-large has 2000+ ops, but which op related to origin layer is hard to figure out.
when you face accuracy problem, you dump the data and compared with what?
or just changed origin network? to get new network output.
Can anyone give me some advice about pytorch?
If your final output is incorrect, the first step I would try is to see what it should be in the original framework.
For example, if your model is in PyTorch, pass some input data, and save the output.
Then, export to TVM, and pass it the same input data. If the output from TVM is different from the original model (with some margin of error for order of floating point ops), then there may be an error in the model importer.
If that’s the case, posting a reproducible example in the TVM forums may help. For example, you mention BERT which is a common model and has several forum users who use it.
If you want to investigate errors yourself, you can compare intermediate results.
For PyTorch, there is this third-party package which saves intermediate results. My earlier posts in this thread about debug_executor showed how to do so in TVM.
what if encounter a fused layer? The SimplifyInference,FuseOps and other Pass make op change. The Norm is a series op composed, and the serires op may fuse with forward or backward op, in such case, the intermediate is hard to compare.
You can disable specific optimization passes (such as SimplifyInference, FuseOps) by passing them as arguments to your build context (where you specify opt_level=3.
You can see all the documented optimization passes, and how to disable them in the docs for tvm.relay.transform.build_config.
Here is an example of using graph debugger: https://github.com/AndrewZhaoLuo/TVM-Sandbox/blob/main/relay/graph_debugger_example.py
The line
with tvm.transform.PassContext(opt_level=3, config={"relay.FuseOps.max_depth": 1}):
lib = relay.build(mod, target=target, params=params)
Will do what Wheest suggests I believe.
disable some pass may be a good idea. as FuseOp pass is a good way to improve performance. In sunch case,

i apply ToMixedPrecision pass to achive better performance, but the result is wrong i found that the Linear op with mixed precision pass make the ir changed to below.
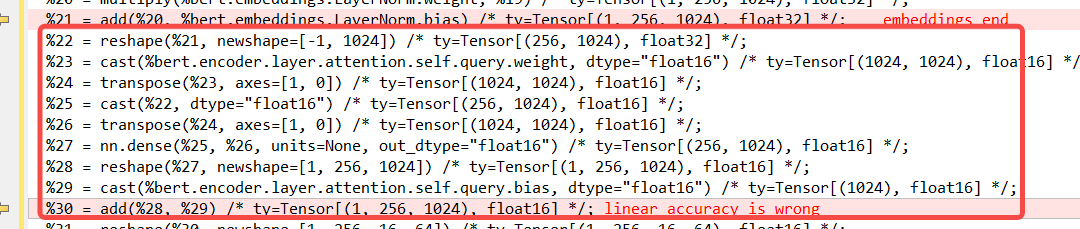
debug_executor sometimes may dump wrong intermediate data, it dumps wrong data. so i analysis the func graph
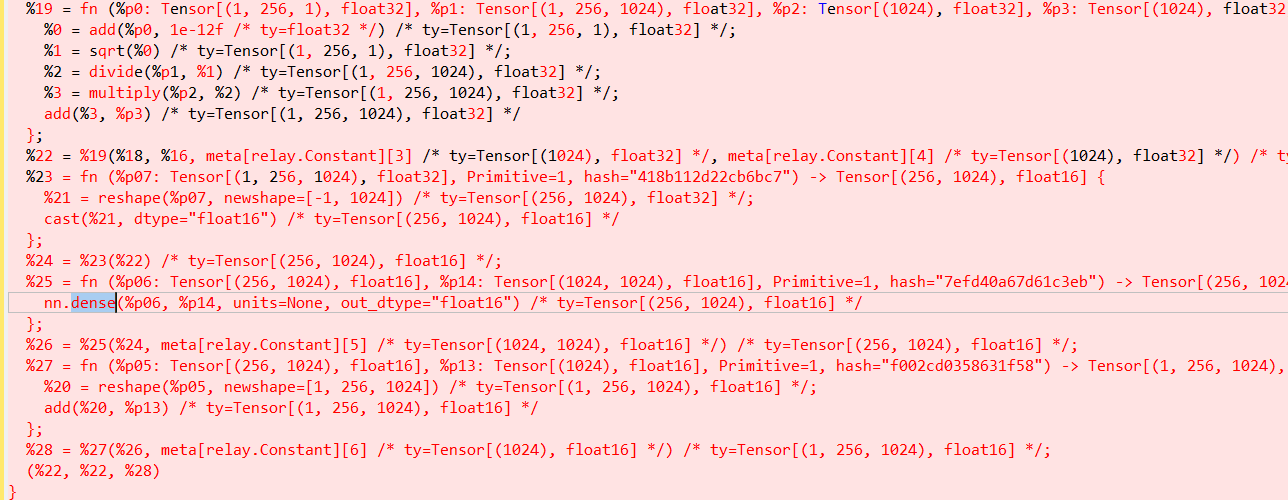
the %22 make it as the result of torch output, so the tvm will make it as one of the output. same to the %28. so the Linear Op with mixed precision changed to 4 ops
@tvmgen_default_fused_add_sqrt_divide_multiply_add = primfn(args_4: handle, arg_type_ids_4: handle, num_args_4: int32, out_ret_value_4: handle, out_ret_tcode_4: handle, resource_handle_4: handle) -> int32
@tvmgen_default_fused_reshape_cast = primfn(args_7: handle, arg_type_ids_7: handle, num_args_7: int32, out_ret_value_7: handle, out_ret_tcode_7: handle, resource_handle_7: handle) -> int32
@tvmgen_default_fused_nn_dense = primfn(args_1: handle, arg_type_ids_1: handle, num_args_1: int32, out_ret_value_1: handle, out_ret_tcode_1: handle, resource_handle_1: handle) -> int32
@tvmgen_default_fused_reshape_add = primfn(args_3: handle, arg_type_ids_3: handle, num_args_3: int32, out_ret_value_3: handle, out_ret_tcode_3: handle, resource_handle_3: handle) -> int32
caus the wrong intermedia data, i can’t decide which op is wrong.
as well i find that the final result with debug_executor is not same with graph_executor sometimes .
Hey @chenugray, let me see if I understand this example. So the concern is that FP16 models using AMP gives incorrect results since it does not match FP32 torch model?
Specifically it’s the one dense layer? Can you dump the expected fp32 tensor and also give what the fp16 tensor is as a .npy? It is hard to say what went wrong and is a difficult problem to debug. Sharing models might make things easier. In general, on many other models (including BERT) we have seen little to no accuracy drop when applying FP16 quantization.
BTW I see your FP16 graph is a little complicated. After applying AMP you should clean up graph by constant folding and running other passes. E.g.
Deciding whether or not results are “correct” when fp16 is involved can be tricky. In my experience, raw outputs are not helpful. I needed to run full evaluation on real data using some accuracy metrics.