Hi, I am a learner at compiler stack, I have a few questions of Tensor IR
instead of TE lower to TIR, what is the process from Relay directly to TIR? it will be better if you have example or tutorial
you mentioned that “Now, there is no stage during the schedule. Rather than lowering the schedule into TIR, we directly mutate the TIR itself.”. is this means there won’t have concept of “lower”, since no stage?
do you have any details of difference between new Tensor IR and former TIR(like TVM 0.6)
I am looking forward for your reply.
Thank you!
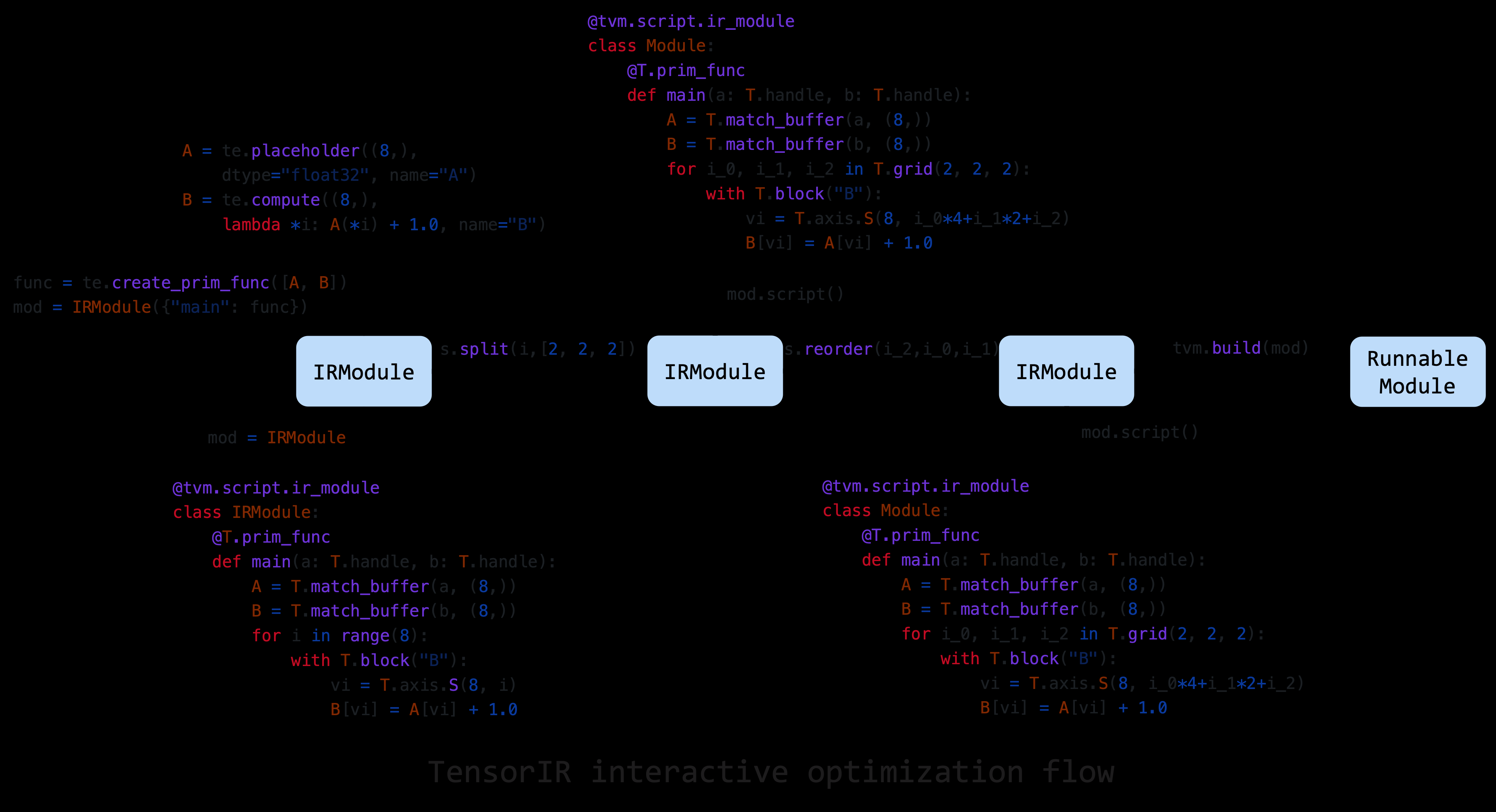
With this proposal landed, There are two ways of lowering Relay:
Relay => TE compute w/ schedule => S-TIR => NS-TIR
Relay => S-TIR => NS-TIR
Effectively, TE compute becomes a syntactic sugar to build S-TIR
is this means there won’t have concept of “lower”, since no stage?
To make sure I understand the question, are you asking why there is no “lower”?
That’s correct. There is no indirection like the TE, where we need to lower the schedule tree into the actual AST after all scheduling is done. Every schedule primitive in S-TIR is effectively a transformation from S-TIR to S-TIR, and the schedule class only provides necessary auxiliary data structures.
do you have any details of difference between new Tensor IR and former TIR
S-TIR is scheduleable while NS-TIR is not;
There is an IR construct called Block in S-TIR, which is introduced in full details in RFC, and is the core concept of how the system works; While in NS-TIR there is not.
@junrushao thank you for your reply, your explanation helps a lot.
but I am a little confused about S-TIR & NS TIR.
can I understand like this:
TF/ONNX/PyTorch => Relay => (with or without TE) => S-TIR => schedule => S-TIR => NS-TIR => code Gen
I still have two father more question about S-TIR:
can S-TIR fully describe an op(e.g. conv), which can replace the TE’s work?
is there any interaction process between S-TIR & NS-TIR?
I am also concerned about if Tensor IR development was finished or is still in process? I am really interensted in this idea, so i’d also like to read some code to understand it better.
S-TIR is a complete IR for the PrimFunc, while TE is just a DSL abstraction. So that S-TIR can fully describe ops which TE can describe. Here is a conv example in S-TIR (The syntax may change as we are discussing the final syntax
# TE
A = te.placeholder((16, 16, 14, 14), name="A")
W = te.placeholder((16, 3, 3, 32), name="W")
Apad = te.compute(
(batch, in_channel, size + 2, size + 2),
lambda nn, cc, yy, xx: tvm.tir.if_then_else(
tvm.tir.all(yy >= 1, yy - 1 < size, xx >= 1, xx - 1 < size),
A[nn, cc, yy - 1, xx - 1],
0.0,
),
name="Apad",
)
rc = te.reduce_axis((0, in_channel), name="rc")
ry = te.reduce_axis((0, kernel), name="ry")
rx = te.reduce_axis((0, kernel), name="rx")
B = te.compute(
(batch, out_channel, size, size),
lambda nn, ff, yy, xx: te.sum(
Apad[nn, rc, yy + ry, xx + rx] * W[rc, ry, rx, ff], axis=[rc, ry, rx]
),
name="B",
)
# S-TIR
@tvm.script.tir
def tir_conv2d(a: ty.handle, w: ty.handle, b: ty.handle) -> None:
A = tir.match_buffer(a, [16, 16, 14, 14])
W = tir.match_buffer(w, [16, 3, 3, 32])
B = tir.match_buffer(b, [16, 32, 14, 14])
Apad = tir.alloc_buffer([16, 16, 16, 16])
for n, c, y, x in tir.grid(16, 16, 16, 16):
with tir.block([16, 16, 16, 16], "Apad") as [nn, cc, yy, xx]:
Apad[nn, cc, yy, xx] = tir.if_then_else(
yy >= 1 and yy - 1 < 14 and xx >= 1 and xx - 1 < 14,
A[nn, cc, yy - 1, xx - 1],
0.0,
dtype="float32",
)
for n, f, y, x, kc, ky, kx in tir.grid(16, 32, 14, 14, 16, 3, 3):
with tir.block(
[16, 32, 14, 14, tir.reduce_axis(0, 16), tir.reduce_axis(0, 3), tir.reduce_axis(0, 3)], "B"
) as [nn, ff, yy, xx, rc, ry, rx]:
with tir.init():
B[nn, ff, yy, xx] = 0.0
B[nn, ff, yy, xx] += Apad[nn, rc, yy + ry, xx + rx] * W[rc, ry, rx, ff]
I’m not sure if there’s any easy way to represent string types, but integers can be represented as T.int32 or T.int64, etc. So in your example, you can probably use the below syntax:
@tvm.script.ir_module
class MyModule:
@T.prim_func
def main(a: T.handle, b: T.handle, x: T.int32):
T.func_attr({"global_symbol": "main", "tir.noalias": True})
A = T.match_buffer(a, (x,), dtype=dt)
B = T.match_buffer(b, (x,), dtype=dt)
...
Note that the TVMScript is a represent for TensorIR (TVM IR) rather than part of runnable python code. That means we can only use TVM data structure (e.g. T.int32, T.handle) rather than python type (e.g. int, str).
Unfortunately, TVM does not have a type hint for type struct (str is not the type struct). So we can not use constants to define buffer types. We may support it in the future if it is needed.
Thanks for the replies! I’m not 100% sure if I understood everything correct.
The feature I’m looking for is to replace TE by TensorIR.
Here an example (from the TVM repository) with lots of parameters defined as Python constants.
The way I interpret the figure from the Blitz tutorial is that I can replace TE by TVMScript(that represents Tensor IR). However, I don’t see the way to use (Python) variables to influence the schedule here.
You have indicated that it might not be possible yet using TVMScript.
Is there another way of bringing the shapes (or type or other constants) of an operator into the TensorIR AST? At least from the tutorial it was not directly clear for me.
IIUC, TVMscript cannot handle such a case. This’s also my question. So I try to modify the TVMscript. The final python snippet is similar as the torchscript:
class ScriptModule(object):
def __init__(self, x: ty.int32):
self.x = x
def main(self, a:ty.handle, b:ty.handle, c:ty.handle)->None:
T.func_attr({"global_symbol": "main", "tir.noalias": True})
A = T.match_buffer(a, (self.x,), dtype=dt)
B = T.match_buffer(b, (self.x,), dtype=dt)
I recommend that you could read the code about torchscript.
IMHO, we can do the same staff like torch script. But like you mentioned before, how to modulize the function may be the main obstacle. Cross function calles may affect codegen, split device and host, etc.
I know that the Blitz tutorial does not show enough information about TensorIR. But it’s a very simple tutorial for the new TVM users, showing how to play with IRModule and TensorIR. More advanced docs and tutorials will come soon after the v0.8 release