Dear colleagues,
I am using the graph_split of test_pipeline_executor, following the official tutorial named Using Pipeline Executor in Relay.
Firstly, I partitioned AlexNet, which does not have branches and multiple data flows. The result is correct.
However, when I am trying to partition the ResNet, which has two data paths, e.g., partitioning after “add” (partition method a, red line) in the following image. The results turned out to be incorrect.
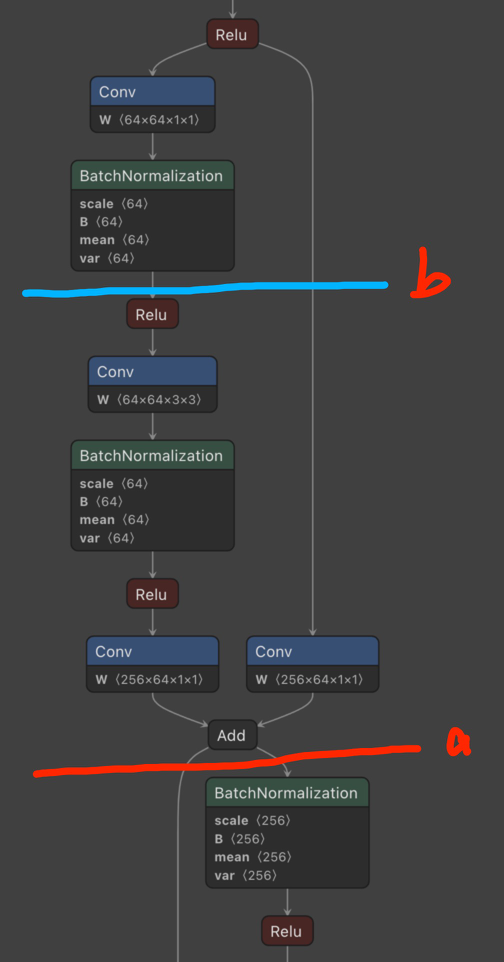
The partitioning code is:
split_config = [{"op_name": "add", "op_index": 0}]
subgraphs = graph_split(mod["main"], split_config, params)
Then I dive into the partitioned IR, I found that:
If we partition after the add op, the Partition 2 will have two input args (namely data_n_0 and data_n_1). However, the partition function does not provide a connection between the output of Partition 1 and the input of Partition 2.
So my questions are:
- How could I simply get the connection between the output of former partition and the input of later partition?
- If I would like to partition after multiple blocks (partition b in the figure), can current
graph_split()oftest_pipeline_executorcan do? If not, how could I perform it? - If I would like to partition using the Fused IR graph, how could I do? I use the following
with tvm.transform.PassContext(opt_level=3):
mod_opt = relay.build(mod, target=target, params=params)
print(mod_opt.ir_mod["main"])
I still can only get the graph with no fused ops. I would like to use the nn_conv2d_relu_xxx as the basic module to partition.
Thank you guys in advance!
Appendix
The partitioned IR of ResNet according to the above description.
def @main(%data: Tensor[(1, 3, 224, 224), float32] /* ty=Tensor[(1, 3, 224, 224), float32] span=resnetv24_batchnorm0_fwd.data:0:0 */) {
%0 = nn.batch_norm(%data, meta[relay.Constant][0] /* ty=Tensor[(3), float32] span=resnetv24_batchnorm0_fwd.resnetv24_batchnorm0_gamma:0:0 */, meta[relay.Constant][1] /* ty=Tensor[(3), float32] span=resnetv24_batchnorm0_fwd.resnetv24_batchnorm0_beta:0:0 */, meta[relay.Constant][2] /* ty=Tensor[(3), float32] span=resnetv24_batchnorm0_fwd.resnetv24_batchnorm0_running_mean:0:0 */, meta[relay.Constant][3] /* ty=Tensor[(3), float32] span=resnetv24_batchnorm0_fwd.resnetv24_batchnorm0_running_var:0:0 */) /* ty=(Tensor[(1, 3, 224, 224), float32], Tensor[(3), float32], Tensor[(3), float32]) */;
%1 = %0.0 /* ty=Tensor[(1, 3, 224, 224), float32] */;
%2 = nn.conv2d(%1, meta[relay.Constant][4] /* ty=Tensor[(64, 3, 7, 7), float32] span=resnetv24_conv0_fwd.resnetv24_conv0_weight:0:0 */, strides=[2, 2], padding=[3, 3, 3, 3], channels=64, kernel_size=[7, 7]) /* ty=Tensor[(1, 64, 112, 112), float32] */;
%3 = nn.batch_norm(%2, meta[relay.Constant][5] /* ty=Tensor[(64), float32] span=resnetv24_batchnorm1_fwd.resnetv24_batchnorm1_gamma:0:0 */, meta[relay.Constant][6] /* ty=Tensor[(64), float32] span=resnetv24_batchnorm1_fwd.resnetv24_batchnorm1_beta:0:0 */, meta[relay.Constant][7] /* ty=Tensor[(64), float32] span=resnetv24_batchnorm1_fwd.resnetv24_batchnorm1_running_mean:0:0 */, meta[relay.Constant][8] /* ty=Tensor[(64), float32] span=resnetv24_batchnorm1_fwd.resnetv24_batchnorm1_running_var:0:0 */) /* ty=(Tensor[(1, 64, 112, 112), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%4 = %3.0 /* ty=Tensor[(1, 64, 112, 112), float32] */;
%5 = nn.relu(%4) /* ty=Tensor[(1, 64, 112, 112), float32] */;
%6 = nn.max_pool2d(%5, pool_size=[3, 3], strides=[2, 2], padding=[1, 1, 1, 1]) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%7 = nn.batch_norm(%6, meta[relay.Constant][9] /* ty=Tensor[(64), float32] span=resnetv24_stage1_batchnorm0_fwd.resnetv24_stage1_batchnorm0_gamma:0:0 */, meta[relay.Constant][10] /* ty=Tensor[(64), float32] span=resnetv24_stage1_batchnorm0_fwd.resnetv24_stage1_batchnorm0_beta:0:0 */, meta[relay.Constant][11] /* ty=Tensor[(64), float32] span=resnetv24_stage1_batchnorm0_fwd.resnetv24_stage1_batchnorm0_running_mean:0:0 */, meta[relay.Constant][12] /* ty=Tensor[(64), float32] span=resnetv24_stage1_batchnorm0_fwd.resnetv24_stage1_batchnorm0_running_var:0:0 */) /* ty=(Tensor[(1, 64, 56, 56), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%8 = %7.0 /* ty=Tensor[(1, 64, 56, 56), float32] */;
%9 = nn.relu(%8) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%10 = nn.conv2d(%9, meta[relay.Constant][13] /* ty=Tensor[(64, 64, 1, 1), float32] span=resnetv24_stage1_conv0_fwd.resnetv24_stage1_conv0_weight:0:0 */, padding=[0, 0, 0, 0], channels=64, kernel_size=[1, 1]) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%11 = nn.batch_norm(%10, meta[relay.Constant][14] /* ty=Tensor[(64), float32] span=resnetv24_stage1_batchnorm1_fwd.resnetv24_stage1_batchnorm1_gamma:0:0 */, meta[relay.Constant][15] /* ty=Tensor[(64), float32] span=resnetv24_stage1_batchnorm1_fwd.resnetv24_stage1_batchnorm1_beta:0:0 */, meta[relay.Constant][16] /* ty=Tensor[(64), float32] span=resnetv24_stage1_batchnorm1_fwd.resnetv24_stage1_batchnorm1_running_mean:0:0 */, meta[relay.Constant][17] /* ty=Tensor[(64), float32] span=resnetv24_stage1_batchnorm1_fwd.resnetv24_stage1_batchnorm1_running_var:0:0 */) /* ty=(Tensor[(1, 64, 56, 56), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%12 = %11.0 /* ty=Tensor[(1, 64, 56, 56), float32] */;
%13 = nn.relu(%12) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%14 = nn.conv2d(%13, meta[relay.Constant][18] /* ty=Tensor[(64, 64, 3, 3), float32] span=resnetv24_stage1_conv1_fwd.resnetv24_stage1_conv1_weight:0:0 */, padding=[1, 1, 1, 1], channels=64, kernel_size=[3, 3]) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%15 = nn.batch_norm(%14, meta[relay.Constant][19] /* ty=Tensor[(64), float32] span=resnetv24_stage1_batchnorm2_fwd.resnetv24_stage1_batchnorm2_gamma:0:0 */, meta[relay.Constant][20] /* ty=Tensor[(64), float32] span=resnetv24_stage1_batchnorm2_fwd.resnetv24_stage1_batchnorm2_beta:0:0 */, meta[relay.Constant][21] /* ty=Tensor[(64), float32] span=resnetv24_stage1_batchnorm2_fwd.resnetv24_stage1_batchnorm2_running_mean:0:0 */, meta[relay.Constant][22] /* ty=Tensor[(64), float32] span=resnetv24_stage1_batchnorm2_fwd.resnetv24_stage1_batchnorm2_running_var:0:0 */) /* ty=(Tensor[(1, 64, 56, 56), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%16 = %15.0 /* ty=Tensor[(1, 64, 56, 56), float32] */;
%17 = nn.relu(%16) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%18 = nn.conv2d(%17, meta[relay.Constant][23] /* ty=Tensor[(256, 64, 1, 1), float32] span=resnetv24_stage1_conv2_fwd.resnetv24_stage1_conv2_weight:0:0 */, padding=[0, 0, 0, 0], channels=256, kernel_size=[1, 1]) /* ty=Tensor[(1, 256, 56, 56), float32] */;
%19 = nn.conv2d(%9, meta[relay.Constant][24] /* ty=Tensor[(256, 64, 1, 1), float32] span=resnetv24_stage1_conv3_fwd.resnetv24_stage1_conv3_weight:0:0 */, padding=[0, 0, 0, 0], channels=256, kernel_size=[1, 1]) /* ty=Tensor[(1, 256, 56, 56), float32] */;
add(%18, %19) /* ty=Tensor[(1, 256, 56, 56), float32] */
}
def @main(%data_n_0: Tensor[(1, 256, 56, 56), float32] /* ty=Tensor[(1, 256, 56, 56), float32] */, %data_n_1: Tensor[(1, 256, 56, 56), float32] /* ty=Tensor[(1, 256, 56, 56), float32] */) {
%0 = nn.batch_norm(%data_n_0, meta[relay.Constant][0] /* ty=Tensor[(256), float32] span=resnetv24_stage1_batchnorm3_fwd.resnetv24_stage1_batchnorm3_gamma:0:0 */, meta[relay.Constant][1] /* ty=Tensor[(256), float32] span=resnetv24_stage1_batchnorm3_fwd.resnetv24_stage1_batchnorm3_beta:0:0 */, meta[relay.Constant][2] /* ty=Tensor[(256), float32] span=resnetv24_stage1_batchnorm3_fwd.resnetv24_stage1_batchnorm3_running_mean:0:0 */, meta[relay.Constant][3] /* ty=Tensor[(256), float32] span=resnetv24_stage1_batchnorm3_fwd.resnetv24_stage1_batchnorm3_running_var:0:0 */) /* ty=(Tensor[(1, 256, 56, 56), float32], Tensor[(256), float32], Tensor[(256), float32]) */;
%1 = %0.0 /* ty=Tensor[(1, 256, 56, 56), float32] */;
%2 = nn.relu(%1) /* ty=Tensor[(1, 256, 56, 56), float32] */;
%3 = nn.conv2d(%2, meta[relay.Constant][4] /* ty=Tensor[(64, 256, 1, 1), float32] span=resnetv24_stage1_conv4_fwd.resnetv24_stage1_conv4_weight:0:0 */, padding=[0, 0, 0, 0], channels=64, kernel_size=[1, 1]) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%4 = nn.batch_norm(%3, meta[relay.Constant][5] /* ty=Tensor[(64), float32] span=resnetv24_stage1_batchnorm4_fwd.resnetv24_stage1_batchnorm4_gamma:0:0 */, meta[relay.Constant][6] /* ty=Tensor[(64), float32] span=resnetv24_stage1_batchnorm4_fwd.resnetv24_stage1_batchnorm4_beta:0:0 */, meta[relay.Constant][7] /* ty=Tensor[(64), float32] span=resnetv24_stage1_batchnorm4_fwd.resnetv24_stage1_batchnorm4_running_mean:0:0 */, meta[relay.Constant][8] /* ty=Tensor[(64), float32] span=resnetv24_stage1_batchnorm4_fwd.resnetv24_stage1_batchnorm4_running_var:0:0 */) /* ty=(Tensor[(1, 64, 56, 56), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%5 = %4.0 /* ty=Tensor[(1, 64, 56, 56), float32] */;
%6 = nn.relu(%5) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%7 = nn.conv2d(%6, meta[relay.Constant][9] /* ty=Tensor[(64, 64, 3, 3), float32] span=resnetv24_stage1_conv5_fwd.resnetv24_stage1_conv5_weight:0:0 */, padding=[1, 1, 1, 1], channels=64, kernel_size=[3, 3]) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%8 = nn.batch_norm(%7, meta[relay.Constant][10] /* ty=Tensor[(64), float32] span=resnetv24_stage1_batchnorm5_fwd.resnetv24_stage1_batchnorm5_gamma:0:0 */, meta[relay.Constant][11] /* ty=Tensor[(64), float32] span=resnetv24_stage1_batchnorm5_fwd.resnetv24_stage1_batchnorm5_beta:0:0 */, meta[relay.Constant][12] /* ty=Tensor[(64), float32] span=resnetv24_stage1_batchnorm5_fwd.resnetv24_stage1_batchnorm5_running_mean:0:0 */, meta[relay.Constant][13] /* ty=Tensor[(64), float32] span=resnetv24_stage1_batchnorm5_fwd.resnetv24_stage1_batchnorm5_running_var:0:0 */) /* ty=(Tensor[(1, 64, 56, 56), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%9 = %8.0 /* ty=Tensor[(1, 64, 56, 56), float32] */;
%10 = nn.relu(%9) /* ty=Tensor[(1, 64, 56, 56), float32] */;
%11 = nn.conv2d(%10, meta[relay.Constant][14] /* ty=Tensor[(256, 64, 1, 1), float32] span=resnetv24_stage1_conv6_fwd.resnetv24_stage1_conv6_weight:0:0 */, padding=[0, 0, 0, 0], channels=256, kernel_size=[1, 1]) /* ty=Tensor[(1, 256, 56, 56), float32] */;
%12 = add(%11, %data_n_1) /* ty=Tensor[(1, 256, 56, 56), float32] */;