Dear developers, I am tuning a Conv1D - CNN model on intel x86 platform. I wrote my own schedule and autotvm tuning template.
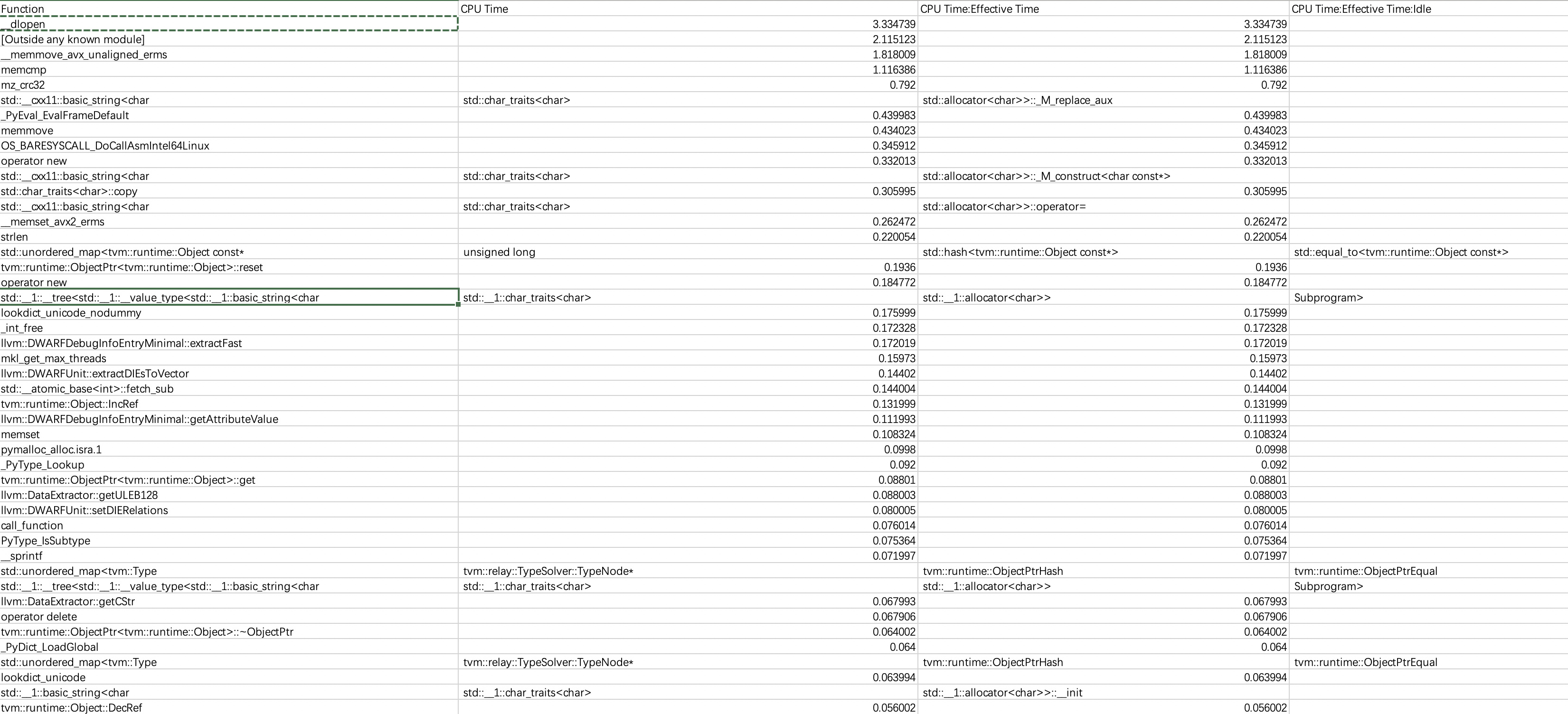
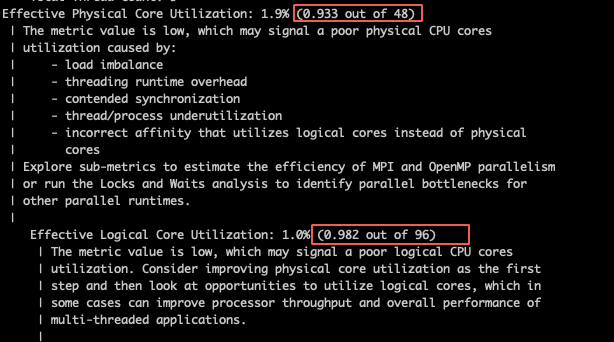
How could I further improve the performance of my schedule ?? I tried tvm debugger but it only displayed the performance of single operator.
I want to further perf the “fused_nn_conv1d_add_nn_relu”.