@jdavies-huawei Thanks for creating this document. This is great. I just went through the same exercise so to understand the InferBound and my notes are not nearly as comprehensive as yours.
Following are some diffs, which I hope shall be useful to you.
Suggested change 1
The following graph illustrates my mental picture of the IterVar Hyper-graph, which I find a bit easier to understand than the circle.
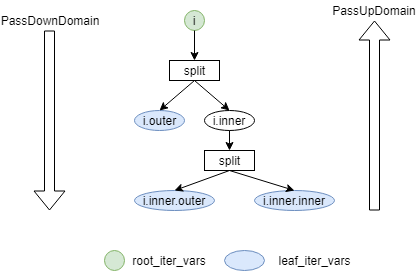
Suggested change 2 / Question 1
I’d suggest the following wording change to the 3rd paragraph of ‘InferRootbound’.
“These IntSets are used to create TensorDom of the output input tensors of the consumer stage (phase3)”.
The reason is that phase 3 computes the TensorDom of all input tensors of the consumer stage, not just the output tensor of the current stage. Is that right?
I notice you also use the term Phase 3: Propagate IntSets to consumer’s input tensors in the later part of the document.
Suggested change 3
This is just a nit.
Maybe move the explanation of PassDownDomain ahead of InferRootBound. This helps explaining where the Range of the IterVars fo the consumer stage come from.
Question 2
How do you generate the output shown in Ex. 4?
The following is what I got by using this method.
// attr [compute(D, 0x15b6460)] realize_scope = ""
realize D([0, 4], [0, 5], [0, 16]) {
produce D {
for (di, 0, 4) {
for (dj, 0, 5) {
for (dk, 0, 16) {
// attr [compute(C, 0x1a0a270)] realize_scope = ""
realize C([dj, 1], [dk, 1]) {
produce C {
C(dj, dk) =5
}
D(di, dj, dk) =(C(dj, dk)*2)
}
}
}
}
}
}
It misses the inner i and j loop nest shown in your exmample.
Suggested change 4
The following text describes how storage scope affects the bound inference. It is adapted from my notes to fit your text flow.
The tensor a stage computes can have a StorageScope, which can be either global (default), shared, warp or local. The StorageScope also affects the result of bound inference.
The StorageScope can be explicitly set by the schedule.set_scope operation, or the cache_write/cache_read operation (if the stage is created by a cache operation), or inferred from the thread bound to an IterVar on the attach_path. The inference rule is
- if any IterVar on the attach_path is bound to
threadIdx,vthreadorcthread, then the scope islocal; - otherwise, if any IterVar on the attach_path is bound to
blockIdx, then the scope isshared; - otherwise, the scope is
global.
During the bound inference, the StorageScope affects the decision whether relaxation is needed or not. From the above (i.e. case 3 of Phase 1 of ‘InferBound with compute_at’), we know relaxation is needed for IterVar’s that are lower on the attach_path than (the attach_ivar). When the storage scope is specified (explicitly or infered), relaxation is also needed for an IterVar on the attach_path if
- the StorageScope is ‘global’ and the IterVar is bound to any thread,
- the StorageScope is ‘shared’ and the IterVar is bound to ‘threadIdx’, or
- the StorageScope is ‘warp’ and the IterVar is bound to ‘threadIdx.x’.
Ex. 6
In the following example, stage B is attached to i of C.
A = tvm.placeholder((200, 400), name='A')
B = tvm.compute((200, 400), lambda i,j: 3.14 * A[i, j], name='B')
C = tvm.compute((100, 200), lambda i,j: 2.72 * B[i, j], name='C')
block_x = tvm.thread_axis("blockIdx.x")
thread_x = tvm.thread_axis("threadIdx.x")
s = tvm.create_schedule(C.op)
i, j = C.op.axis
s[C].bind(i, block_x)
s[C].bind(j, thread_x)
s[B].set_scope("shared")
s[B].compute_at(s[C], i)
ib, jb = s[B].op.axis
s[B].bind(jb, thread_x)
The j is lower on the attach_path, therefore is relaxed and has extent 200. B([blockIdx.x, 1], [0, 200]) needs to be realized.
realize C([0, 100], [0, 200]) {
produce C {
// attr [iter_var(blockIdx.x, , blockIdx.x)] thread_extent = 100
// attr [compute(B, 0x19def60)] realize_scope = "shared"
realize B([blockIdx.x, 1], [0, 200]) {
produce B {
// attr [iter_var(threadIdx.x, , threadIdx.x)] thread_extent = 200
B(blockIdx.x, threadIdx.x) =(3.140000f*A(blockIdx.x, threadIdx.x))
}
// attr [iter_var(threadIdx.x, , threadIdx.x)] thread_extent = 200
C(blockIdx.x, threadIdx.x) =(2.720000f*B(blockIdx.x, threadIdx.x))
}
}
}
extern "C" __global__ void test_kernel0( float* __restrict__ A, float* __restrict__ C) {
__shared__ float B[200];
B[((int)threadIdx.x)] = (A[((((int)blockIdx.x) * 400) + ((int)threadIdx.x))] * 3.140000e+00f);
C[((((int)blockIdx.x) * 200) + ((int)threadIdx.x))] = (B[((int)threadIdx.x)] * 2.720000e+00f);
}
Ex. 7
The following code is exactly the same as that in Ex.6, except that stage B is attached to j of C instead of i of C.
A = tvm.placeholder((200, 400), name='A')
B = tvm.compute((200, 400), lambda i,j: 3.14 * A[i, j], name='B')
C = tvm.compute((100, 200), lambda i,j: 2.72 * B[i, j], name='C')
block_x = tvm.thread_axis("blockIdx.x")
thread_x = tvm.thread_axis("threadIdx.x")
s = tvm.create_schedule(C.op)
i, j = C.op.axis
s[C].bind(i, block_x)
s[C].bind(j, thread_x)
s[B].set_scope("shared")
s[B].compute_at(s[C], i)
ib, jb = s[B].op.axis
s[B].bind(jb, thread_x)
Without considering the storage scope, j would not be relaxed. In this case, however, the storage scope of B is shared and j is bound to threadIdx. Therefore j is relaxed and has extend 200. B([blockIdx.x, 1], [0, 200]) needs to be realized, as it does in Ex. 6.
realize C([0, 100], [0, 200]) {
produce C {
// attr [iter_var(blockIdx.x, , blockIdx.x)] thread_extent = 100
// attr [iter_var(threadIdx.x, , threadIdx.x)] thread_extent = 200
// attr [compute(B, 0x19af470)] realize_scope = "shared"
realize B([blockIdx.x, 1], [0, 200]) {
produce B {
B(blockIdx.x, threadIdx.x) =(3.140000f*A(blockIdx.x, threadIdx.x))
}
C(blockIdx.x, threadIdx.x) =(2.720000f*B(blockIdx.x, threadIdx.x))
}
}
}
extern "C" __global__ void test_kernel0( float* __restrict__ A, float* __restrict__ C) {
__shared__ float B[200];
B[((int)threadIdx.x)] = (A[((((int)blockIdx.x) * 400) + ((int)threadIdx.x))] * 3.140000e+00f);
C[((((int)blockIdx.x) * 200) + ((int)threadIdx.x))] = (B[((int)threadIdx.x)] * 2.720000e+00f);
}
Ex. 8
The following code is exactly the same as that in Ex.6, except that storage scope of B is not explicitly set but infered.
A = tvm.placeholder((200, 400), name='A')
B = tvm.compute((200, 400), lambda i,j: 3.14 * A[i, j], name='B')
C = tvm.compute((100, 200), lambda i,j: 2.72 * B[i, j], name='C')
block_x = tvm.thread_axis("blockIdx.x")
thread_x = tvm.thread_axis("threadIdx.x")
s = tvm.create_schedule(C.op)
i, j = C.op.axis
s[C].bind(i, block_x)
s[C].bind(j, thread_x)
# s[B].set_scope("shared")
s[B].compute_at(s[C], i)
ib, jb = s[B].op.axis
s[B].bind(jb, thread_x)
The lowered and generated code is the same as that in Ex. 6.
realize C([0, 100], [0, 200]) {
produce C {
// attr [iter_var(blockIdx.x, , blockIdx.x)] thread_extent = 100
// attr [compute(B, 0x198f070)] realize_scope = ""
realize B([blockIdx.x, 1], [0, 200]) {
produce B {
// attr [iter_var(threadIdx.x, , threadIdx.x)] thread_extent = 200
B(blockIdx.x, threadIdx.x) =(3.140000f*A(blockIdx.x, threadIdx.x))
}
// attr [iter_var(threadIdx.x, , threadIdx.x)] thread_extent = 200
C(blockIdx.x, threadIdx.x) =(2.720000f*B(blockIdx.x, threadIdx.x))
}
}
}
extern "C" __global__ void test_kernel0( float* __restrict__ A, float* __restrict__ C) {
__shared__ float B[200];
B[((int)threadIdx.x)] = (A[((((int)blockIdx.x) * 400) + ((int)threadIdx.x))] * 3.140000e+00f);
C[((((int)blockIdx.x) * 200) + ((int)threadIdx.x))] = (B[((int)threadIdx.x)] * 2.720000e+00f);
}